You will need Kubernetes clusters to run readers, data pipelines, and writers. There is a question about whether we should use a big Kubernetes cluster or several smaller ones. This design issue is out of the scope of Calabash.
For production, you should spend sufficient time deciding the configuration of the clusters. Then use Calabash or any other tool to create them.
In this tutorial, we will only create one Kubernetes cluster. And we will share it among readers, data pipelines, and writers.
To start, in the Calabash GUI, go to the “Infrastructure” page and click on the “Create Infrastructure Object.” Fill in the form like the following.
Select the type as “Kubernetes Cluster,” and the remaining form changes to show parameters for the cluster.
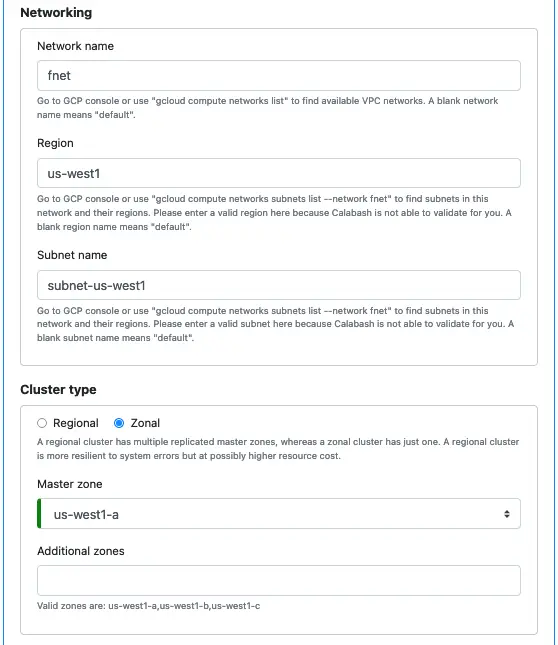
Next, describe the networking and cluster type.
You do not have to fill in the networking part precisely as the above. Any network and subnet will do.
The cluster type should be zonal for containing the cost for the tutorial. For production, it is necessary to spend some time understanding the differences between regional and zonal clusters. Then make the most suitable choice for your situation.
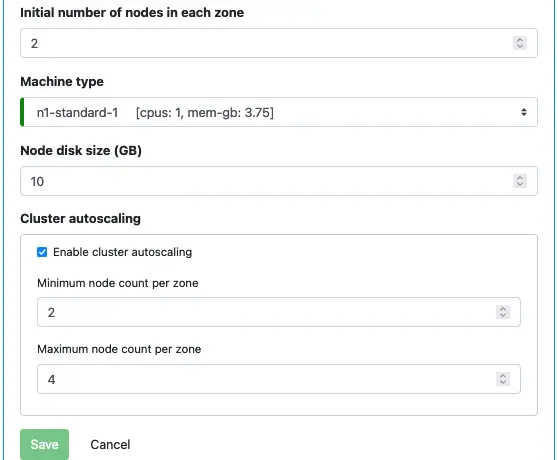
Finally, we set various sizing parameters.
The parameters shown above are best for the tutorial. It is the minimum configuration.
To deploy the Kubernetes cluster, use the Calabash CLI.
Calabash (jdoe:lake_finance)> deploy i lf-cluster1
Cluster created, checking for K8s service endpoint...
Checking status of k8s api service... retries remain: 30
Checking status of k8s api service... retries remain: 29
Checking status of k8s api service... retries remain: 28
Checking status of k8s api service... retries remain: 27
Deployed to 35.203.149.23
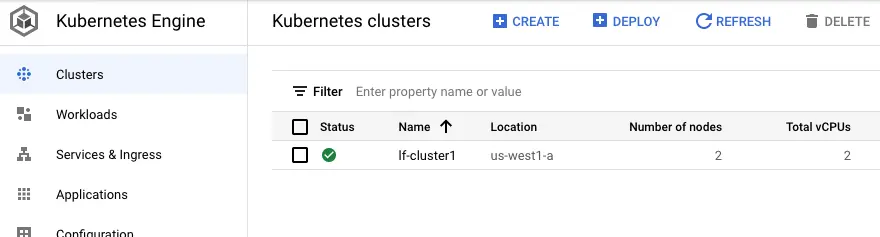
The actual creation process may take some time. Please go to the Google Cloud Console to check the status. Make sure there is a green check mark under the status (like the following screenshot) before you process to the next part of the tutorial.
The Kubernetes cluster will be the biggest resource in the tutorial. Its cost is determined by the number of nodes deployed. Most of time, there are only two nodes. But when all the reader, data pipelines, and writer run at the same time, the number of nodes could grow to four.
In the worst case, the cost is about $100/mo. You can reduce the cost significantly by undeploying the cluster using Calabash CLI, when you do not need it:
Calabash (jdoe:lake_finance)> undeploy i lf-cluster1
Cluster lf-cluster1 deleted.
Undeployed
2 thoughts on “Track 3 Topic 2: Create a Kubernetes Cluster”
This is the right website for anybody who wants to find out about this topic. You understand a whole lot its almost tough to argue with you (not that I personally would want toÖHaHa). You definitely put a new spin on a topic which has been written about for years. Excellent stuff, just excellent!

2 thoughts on “Track 3 Topic 2: Create a Kubernetes Cluster”
This is the right website for anybody who wants to find out about this topic. You understand a whole lot its almost tough to argue with you (not that I personally would want toÖHaHa). You definitely put a new spin on a topic which has been written about for years. Excellent stuff, just excellent!
Right on my man!
Comments are closed.