1. Stop the Reader
You can use the KCE “connector_pause” command to suspend a reader. The format of the command is:
./connector_pause.sh ADMIN_USER KAFKA_CONNECT_IP CONNECTOR_NAME
where KAFKA_CONNECT_IP is the IP address of Kafka-Connect service (which listens at port 8083). You can find the Kafka-Connect service IP from the project metadata or from the status of the Kafka infrastructure object.
The CONNECTOR_NAME is the reader’s name. All Calabash readers, except the API Service reader, are Kafka-Connect-based. And the reader name is used as the connector name.
This command does not have a return message if all goes well.
If the reader is an API service reader, there is no Kafka connector to pause. You have to undeploy the reader. Your application using the API service will start to experience timeouts. They should redirect data elsewhere, such as saving them to a local disk or cloud storage.
You may also undeploy a Kafka-Connect-based reader. Kafka-Connect persists the “reader offset.” Next time you deploy the reader again, it will continue from the persisted offset. There is no worry of duplicates or data loss.
To check the reader offsets, you can use the KCE “list_reader_offset” command.
Finally, the root problem in the backpressure emergency is not the reader in most cases. You have to examine pipelines and writers for the non-stop increase of lags. But the reader is the driving force of the data flow. So we stop the reader and gain some time to fix the issues.
2. Increase Parallelism
Sometimes the reason for slow pipeline or writer is simply because of lack of processing power. This situation can be diagnosed with Kubernetes and OS performance tools.
If the cause is the lack of resources, you should increase the number of pods for a pipeline or increase the number of workers for a writer.
To increase the number of pods, modify the property of the pipeline:
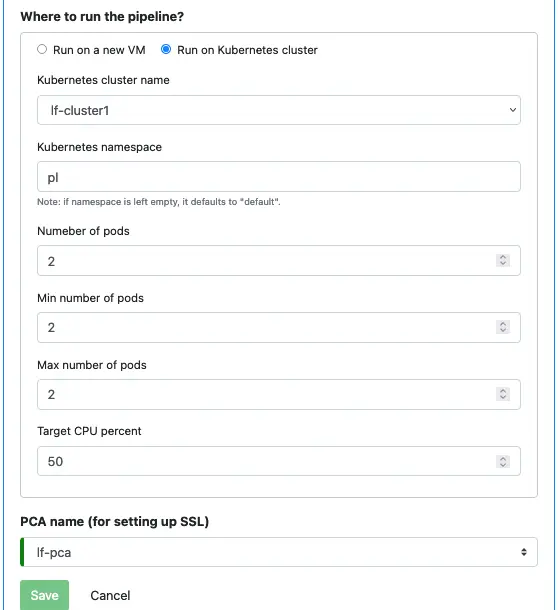
In the above screenshot, you should increase both “Number of pods” and “Max number of pods.”
Here is how to modify the number of workers for a writer:
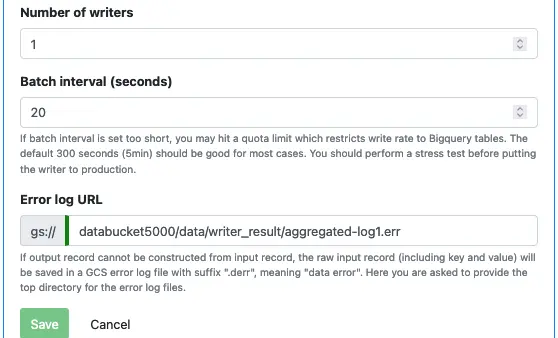
To put the modified degree of parallelism into work, first, undeploy the pipeline or writer. Then deploy it again. Kafka persists the consumer group offsets, so the process will resume from where it left off.
If the increasing degree of parallelism still does not fix the problem. You may have encountered restrictions on topic partitions. The number of topic partitions is a hard limit on consumer parallelism.
To increase the number of partitions, you must recreate the topic. First, wait till the lags on it all reach zeros. Then use the KCE “delete_topic” command to drop it. Then use the KCE “create_topic” to create it again. This time with more partitions.
3. Persist Data
Due to the transient nature of the Kafka topic, you have a fixed amount of time to fix any pipeline and write problems. Read the explanation in Plan for Unexpected: Preprocessing Backup for details.
If you think resolving the issues will likely take a long time, it is time to start the preprocessing backup writer.