1. Plan for Preprocessing Backup
The topics in your Kafka system are not equal. The ones that receive data from readers are the driving forces of your data flows. The sink targets of pipelines are in another group of topics. These topics receive data passively from upstream.
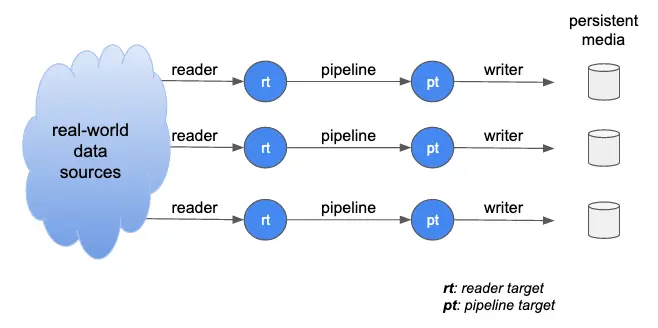
In the above illustration, circles represent topics. There are reader-target topics and pipeline-target topics. The diagram has simplified the pipeline system. In reality, you may have cascading pipelines.
In the ideal world, the data flows would never experience hiccups. But that we can only wish.
One bad situation is the pipeline/writer cannot keep up with the reader due to an unexpected problem. If this happened, data would accumulate in the rt or pt. Kafka retains data in topics for seven days by default. You can configure a longer retention time, but that is not the solution. By the end of the retention period, if the pipeline or writer problem persists, you will start to lose data.
A solution is to create writers to immediately write data from rt to persistent media. Take writing to Google Cloud Storage as an example. Files written to the cloud storage by a CSV file writer will have timestamped file paths, such as
gs://mybucket/writer-target/rt-backup1/2021/08/03/20210803_182004.csv
When you have fixed the pipeline or writer problem, you can selectively load (by deploying readers) from these files to rt. Creating backup writers for all rt’s is a plan for the worst-case. In reality, you may weigh on the importance of the topics. Create the backup writers for the most critical ones.
Another solution moves the above backup idea into data sources. Instead of using readers to directly receive data from devices/databases/API/etc., ask your source users to save their data to the cloud storage. Then design Calabash readers to read from the storage media. In other words, we use cloud storage as a buffer with virtually unlimited capacity. In case of a crash in our data system, no data will ever be lost. Kafka’s retention window becomes an irrelevant factor.
Kafka keeps the processing metadata for readers, pipelines, and writers. As soon as the system is back from a crash, it resumes and continues from where it left off.
The problem with the second solution is some burdens to your user. For example, your database user must export data to the cloud storage. Some effort is necessary, but the return will outweigh the investment.
Finally, you may consider mixing and matching the two solutions for different topics. The moral here is that the Kafka system is transient, albeit with long transience. The worst-case solution calls for backup storage with a much longer duration.
2. Plan to Automate Error Correction
In some less disastrous (but still severe) cases, you may encounter massive processing errors. Calabash has implemented a strategy not to lose any data. The readers, pipelines, and writers can all capture any exceptions. Upon catching an exception, they will send the error message to the error topics, together with the raw record that causes the error.
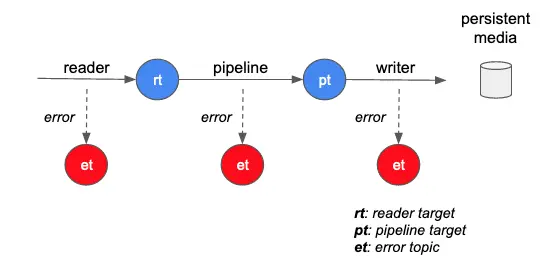
In the above diagram, the dashed arrows to the error topics mean the flows to et are optional. If no error topic is specified, there will be no error reporting feature. In such a case, erroneous data will disappear silently from the flow. You should examine every error reporting point in the design to decide if you can afford such losses.
What can you do if you have caught errors in the et? It is not a good idea to manually correct data since the amount of data could be prohibitive. You can create data pipelines to read from the et, fix the error, then write good data to other topics. Or, you could deploy writers to save the error records to persistent media. You will then have more time for postmortem.
Planning what to do with the errors require time and careful thought. You want to focus on automating the error resolution. Calabash has laid the foundation for this automation.
3. Plan a Standby System
You can use Calabash GUI to create a replica data system. The standby replica serves two purposes.
- Test and debug problems in the production system.
- Switch over from the production.
In some extreme cases, the production system hits an unrecoverable problem. You may have no choice but to abandon it. However, you often do not want to wipe it out right away. In such cases, a fully-tested standby system is the next best thing for you.
The standby data system does not have to operate full-time. You can design and test it. Then undeploy it. You can quickly put it in place using Calabash CLI when you need it.