This article is an introduction to data lakes and how this concept relates to Calabash.
Strictly speaking, a data lake is a strategy. It guides us in doing data preparation for data analyses and data discovery in a big-data system. For a discussion on challenges from big data, please read the article What is Big Data.
The data lake strategy is the crystalization of decades of lessons from building data systems for the digital world teeming with surprises. As explained in What is Big Data, traditional database and data warehousing solutions hit roadblocks. They need help from a newcomer called “data lake.”
1. The Primary Goal: Replicate Real World
The primary goal of a data lake is to replicate the real-world (i.e., the data sources) in real-time 24 by 7. The data capturing phase of a data lake spends no time in determining the good-bad-ugly nature of the data. They are all treated equally.
A cloud-based architecture is a preferred setup. Cloud technology has evolved to a stage where it can be more secure and faster than most data systems on-premises. The shared model of the cloud, if harnessed correctly, could make resources available quickly at much lower costs.
The storage cost, per se, has been decreasing exponentially in recent years. We now have more technology than we need to record every happening in the world and make the data available everywhere. All done securely and efficiently.
2. The Secondary Goal: Purify Data
The secondary goal of a data lake is to purify data in real-time. To that end, a big-data system employs a new technology known as “data pipeline.”
A data pipeline has the following characteristics.
- Data-driven. It must almost instantly detect data arrival, and it must consume nearly no resource when being idle.
- Real-time. It must be able to process data right away as they are detected. And the processing speed must keep up with the data rate, or you have created a “data stop,” not a conduit.
- Self-healing. It must be able to automatically recover from system failures and continue from where it left off.
Creating data pipelines with the above characteristics is challenging but rewarding as well. The data pipelines take over a majority of data quality responsibilities. You can save a lot of time and money if this part of your big-data system is automated.
3. Look Inside: Data Ponds
Pipelines organize a data lake into “data ponds” with different levels of purity.
The raw data just ingested into a data lake form a “dirty pond.” The data in this pond are dirty primarily because it contains the highest number of human errors and because of their structure-less rawness.
A pipeline can parse the raw data and identify data structures. The parsed result is a pond of cleaner data, with, e.g., some new fields recognized or some bad records dropped. You may continue with this idea indefinitely by adding more pipelines, generating increasingly cleaner ponds. This process ends when there is no need to purify the data further. The final result is your “pristine pond.”
Imagine if you drew some sample “water” from your ponds, you would see something like this below.

The dirty pond contains dark particles, which are absent from the clean pond. The pristine pond shows deeper blue because it holds concentrated “good stuffs” as the results of aggregations.
Because of dedup, filter, and aggregation in data pipelines, the pond size decreases going downstream. The pristine pond is the smallest, but it has the highest usefulness.
4. Look Inside: No Joins
Data pipelines avoid doing joins to keep processing time predictable. If the worst-case processing time is known, we can configure the runtime to avoid pipeline stalls.
A join of real-time data streams is almost impossible to get right. A successful join depends on the relative speeds of component streams. There is always a risk of indefinite waiting or running out of resources.
But what should you do if a join is needed? The principle is to use the right tool for the job. A scalable batch processing tool, such as Spark, is best suited for processing massive joins, groupings, and aggregations in a short amount of time.
5. Look Outside: Where is the Data Lake?
In general, a big-data system has both real-time and batch processing portions. The data lake is its real-time component. The following illustration is for the entire big-data architecture, using Spark as an example for its batch processing part.
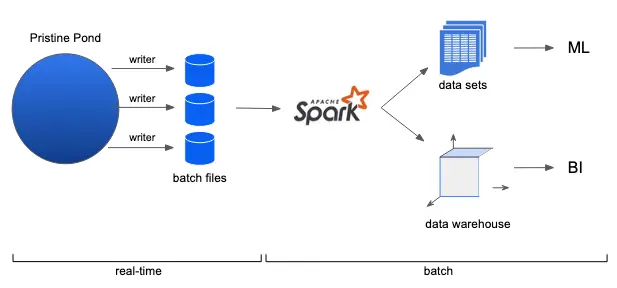
There are two primary use cases for the batch processing component.
- Create data sets for machine learning. The prerequisite for ML is the availability of denormalized (i.e., massively joined) data sets since we must not assume any structure in the data.
- Load data warehouse for business intelligence. A data warehouse is a data structure for massively pre-joined and pre-aggregated data.
The best batch processing tool, such as Spark, can (or can be configured to) complete the job in constant time regardless of the input size. This feat is not achievable in real-time.
With the presence of the data lake, a performance booster for the entire big-data system is to move as much as possible data quality processing to pipelines in the data lake. This way, the complexity of data preparation is amortized, and the batch portion always uses good data.
A data lake is a big data solution for its own sake because it must swallow the highest volume in the system. It must also deal with data variety and veracity, i.e., validate data structures and convert unstructured data streams to structured ones. A well-designed data lake is a key to meeting all big-data challenges.
6. Look Further: A Software Engineering Challenge
A data lake must be real-time from end to end because there is no identifiable break time or maintenance windows. Since a data lake indiscriminately accepts all data, including potentially highly confidential records, it must operate with the highest security protection.
Implementing data processing logic also requires metadata management support, i.e., defining and tracking data types down the pipeline paths. All these require top-notch software engineering skills.
Building a data lake is difficult, even for highly experienced software developers. But this challenge will cease to exist if you use Calabash, an online tool for building data lakes.
Using Calabash, you will not write code for ingesting raw data into the data lake, and you will not write implementation code for pipelines. All you need to do is specify where the sources are and what you intend to do in the data pipelines. You create these specifications by filling out some high-level forms in the interactive Calabash GUI. Calabash will generate implementation code (in Java) for you, and it will build libraries and deploy them to the cloud platform when you issue the “deploy” command in Calabash CLI. There is also an “undeploy” command for removing deployed processes and clean up cloud resources.
The data lake built using Calabash has the highest level of security protection you can ask for. All network communications are encrypted using a private certificate authority, and two-way TLS authentication is implemented everywhere. On top of that, there are token-based authorizations. Furthermore, there are also ACL-based (Access Control List) internal authorizations. And finally, anything that must be saved on storage or transmitted over the network is encrypted.
Data Canals employs highly experienced software developers to build Calabash. They have experiences covering the entire modern-day big-data evolution. You will be putting their valuable experiences to work for you when you use Calabash.
For details of Calabash, please read the article Calabash Architecture, then follow the links there for information about Calabash GUI and Calabash CLI.