The mission of Calabash is to help users build data lakes without having to first acquire advanced IT skills or deep software development expertise. A data lake is a real-time data system performing data collection and processing.
For example, users do not need admin-level skills in Kafka. But they can still build and manage Kafka systems using Calabash. Users do not need to know anything about Kafka Streams. But they can create complicated processing logic in Kafka Streams with the Calabash code generator. Users can also make their data systems the most secure in the cloud by deploying the so-called “private certificate authority” (PCA). They do not need to know all the details. Using Calabash, users can eliminate the technical “necessary devil” and focus their attention on the data processing logic.
We have other articles covering the theory of data lake extensively. So this article will discuss the usages of Calabash from a different angle: we will look at specific tasks Calabash can help users accomplish. These are:
- Collect data from anywhere in real-time
- Save data from Kafka to anywhere in real-time
- Process data in real-time using Kafka Streams
- Secure users data systems
- Set up a Kafka system
- Manage a Kafka system
- Create microservices/websites
- Cut cloud usage costs
In every use case, Calabash makes achieving your goals drastically easier. Moderately trained staff with basic Java knowledge can complete work previously reserved for highly experienced engineers. They can also do it fast with high quality.
1. Calabash Helps Users Collect Any Data in Real-Time
Gathering data for processing is called “data ingestion.” It is an often overlooked engineering phase. A traditional doctrine mandates that only “important” data should be collected because we once had limited storage and processing capacity. Also, avoiding “garbage in garbage out” has been a golden rule for decades in the data processing arena.
But nowadays, we often have difficulty telling good data from garbage. Machine learning/AI algorithms also require that we do not make a premature judgment on the importance of data. In a sense, collecting all data in real-time becomes a modern-day requirement for most businesses. Luckily, the computing resources have become literally unlimited in the cloud. We do have the material foundation for collecting everything as it happens. What is missing is a software tool helping users do this easily.
Using Calabash, users with little exposure to the underlying technology can quickly create data collection processes (called “readers”). The implementation code is generated when the readers are deployed to the cloud. See the following illustration.
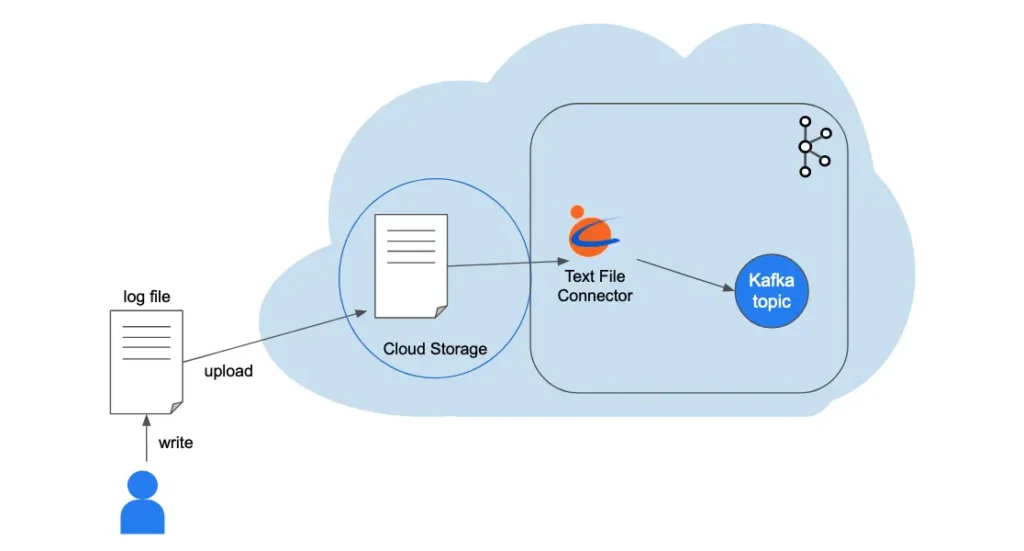
Suppose your business (through humans or applications) writes event logs to a textual log file with one event per line. You can use Calabash to deploy a “Kafka text file connector.”
This connector watches a file location on the cloud storage. It identifies new text lines and sends them to a Kafka topic as records.
All you need to do is to upload the log file to the cloud storage location from time to time. New data are instantly identified and loaded to the Kafka topic. There will be no duplicates.
But why do we want to load data into Kafka? A good reason is to consolidate data from many sources into one place. But the more compelling reason is to process data in real-time. This is the essence of the big data solution. With real-time processing, we can “amortize” the load, and we can nibble away large amounts of data using cheaper hardware.
Once the data are in the Kafka topic, you can use Calabash to create data pipelines to instantly process them. You can also save them to persistent media with writers. We will talk about these in the following two use cases.
Currently, Calabash offers these Kafka source connectors:
- Text file reader
- Binary file reader
- Avro file reader
- Parquet file reader
- Microsoft Excel file reader
- Google Sheets reader
- JDBC query reader
If what you need is not on the available readers’ list, you can contract Data Canals to create a special connector for you.
Calabash also offers a reader that is not a Kafka connector. It is called “API Service Reader.” This reader will launch a microservice to receive HTTP POST messages. It then saves them to the Kafka topic as records. Essentially, it wraps the Kafka topic with an HTTP listener. Using REST requests will be a lot easier than accessing Kafka directly. Furthermore, Calabash also helps you add TLS (SSL) and access control on the API service.
For a detailed account of the Calabash readers, refer to the article Collect Data to Kafka without Writing Code.
2. Calabash Helps Users Save Data from Kafka Topics to Anywhere
Data stored in Kafka topics have a seven-day lifespan. By the end of the seventh day, they may start to give way to new data. You will always need to create processes to save your valuable data to permanent media.
Calabash helps you create such processes, called “writers.” Similar to creating readers, you create writers using an easy-to-use web GUI. No coding is required.
Currently, all Calabash writers are Kafka sink connectors. The following is a list of all available Calabash writers.
- CSV file writer
- JSON file writer
- Avro file writer
- Parquet file writer
- JDBC table writer
- Google Bigquery writer
- API target writer
If what you need is not on the available writers’ list, you can contract Data Canals to create a special connector for you.
The last one, the “API target writer,” will send each record to a REST API of your choosing. The sending of API requests happens in real-time. A message is sent as soon as the writer sees a new record in the Kafka topic.
The following illustration describes one specific implementation.
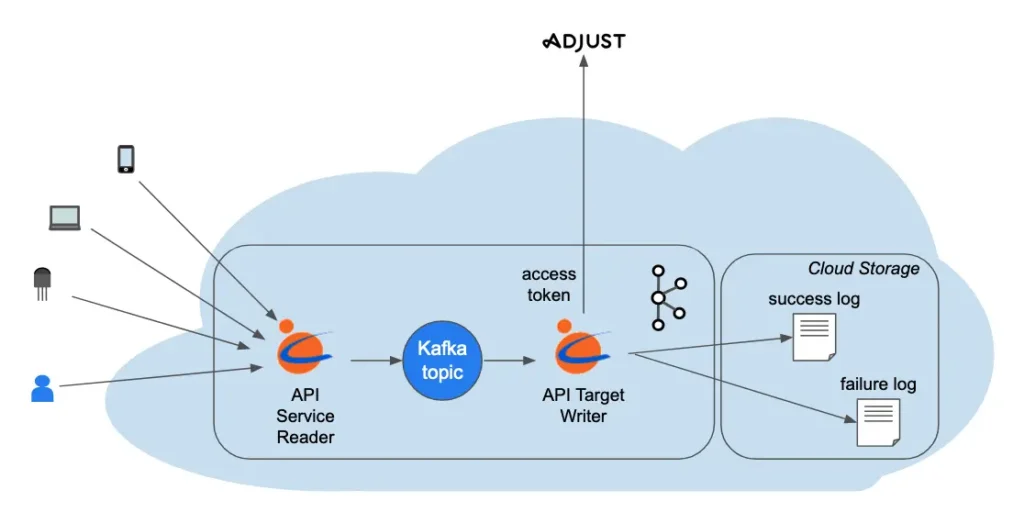
Adjust is a third-party app event tracking and financial attribution site. Its “food” is the events in your system. After some “digestion,” it gives you insights into where your financial success/failure is coming from.
The events are fed to the Adjust service through an access-token-controlled REST API. We created a Calabash API target writer, as shown above. This Kafka sink connector watches a Kafka topic in real-time and sends each record to Adjust in an HTTPS POST request.
The writer saves status information about the requests, regardless of whether they succeeded or not. The status logs are stored in cloud storage files for easy access.
As shown in the above diagram, events are funneled to the Kafka topic from everywhere in the company. The chances for mistakes are relatively high.
From time to time, the analysts in the company felt the result calculated by Adjust was an impossible surprise. They suspected some events may be missing or sent twice. The success/failure logs proved to be indispensable in the investigation.
The Adjust server keeps status about failed requests, but it does not save information about successful ones. So we had to keep the success log ourselves for possible investigations into duplicate/missing messages.
In the above illustration, all apps running on mobiles, PCs, or other devices use the standard HTTP protocol to send events to the “API Service Reader.” And they leave the details of accessing Adjust API to the writer. They could also directly send events to Adjust, but it would require company-wide developer training on Adjust API. It would also not be future safe.
For a more detailed account of the Calabash writers, please read Save Data from Kafka without Writing Code.
3. Calabash Helps Users Process Data with Kafka Streams
Kafka is notorious for being complicated. Its real-time processing capability, known as Kafka Streams, is even more demanding. Calabash has solved this usability issue completely.
Calabash offers a straightforward GUI interface for users to design data pipelines. Users do not even have to know what Kafka Streams is. Calabash will generate and deploy Kafka Streams code based on users’ pipeline designs.
The users, however, do need to have some basic Java skills. They will need to write Java expressions in the processing logic. These expressions are directly tied to the business logic they want to implement. For example, a filter condition, a calculation of output field using input fields, a call to a third-party library, etc.
In summary, Calabash takes away the burden of the Kafka Streams from users 100% and, at the same time, provides the users 360-degree freedom in implementing their business logic. See the illustration below.
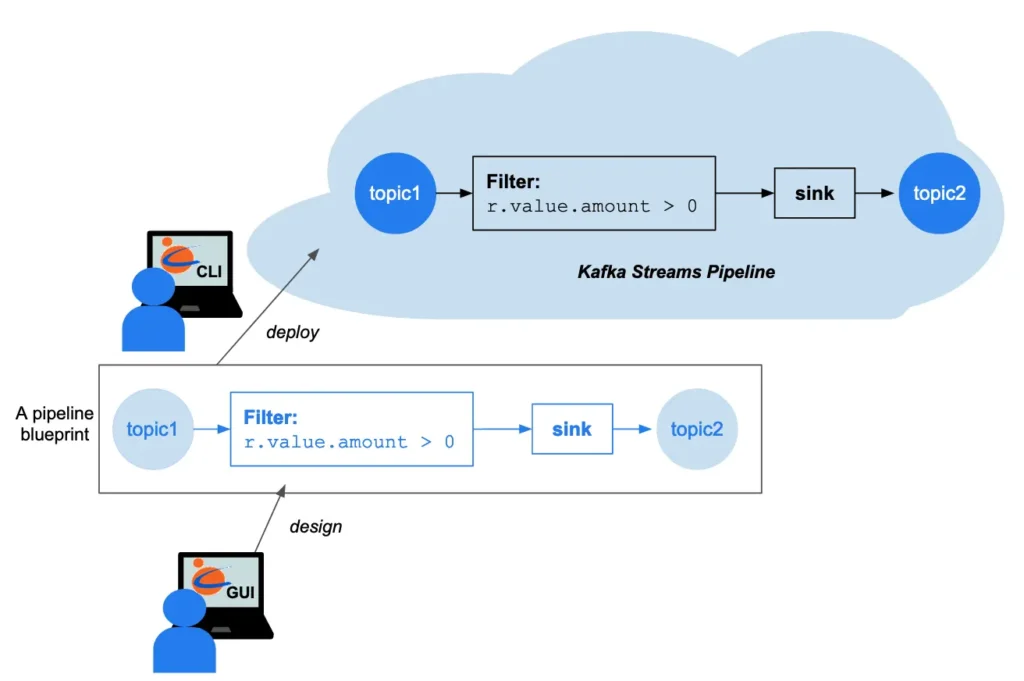
The Calabash GUI is a web-based design tool for creating pipeline blueprints. Calabash CLI (command line interface) is for code generation and deployment to the cloud.
The above illustration gives you a glimpse of what a data pipeline looks like. A data pipeline starts with a Kafka topic and has a chain of processors. A Filter is a straightforward processor that subjects each record to a boolean condition. The user enters a Java expression for the filter condition. A pipeline always ends with a sink processor which sends data to another Kafka topic.
Calabash supports the following types of processors
- Filter
- Deduplication
- Record transformation
- Group transformation
- Sink
These are sufficient for composing any processing logic.
Calabash is a complete development platform for real-time data processing. You may create as many pipelines as you like and any number of processors you need. Traditionally, this is called an “ETL” (Extract Transform and Load) tool.
However, the traditional ETL (or its more modern variant, ELT) implies batch data processing. The ETL processing created by Calabash, however, is real-time. Each data record instantly goes through a series of processing stages to get cleansed, transformed, and enriched. The overall idea is to amortize the data quality processing to combat the big data challenge. (For an overview of Big Data challenges, please refer to the article What is Big Data.)
But what if some stages hit errors? In the real world, this is a legitimate question. Calabash captures all errors and sends messages to the so-called “error topics.” You can design your error detection and correction strategies in Calabash GUI. Currently, Calabash is the only platform supporting real-world-oriented data engineering using the Kafka systems.
For more details, please read A Simple GUI for Kafka Streams.
4. Calabash Helps Secure User's Data Systems
In a production environment, communications among nodes must be encrypted, access to services must be authorized. These are not straightforward matters to even experienced engineers.
Calabash makes it easy for users to secure their data systems with the Private Certificate Authority (PCA). A PCA is a service deployed to a virtual machine (VM). Its purpose is to sign TLS (SSL) certificates.
Nodes in a data system can trust each other with signed certificates from the same PCA. They can also encrypt messages using the keys and certificates.
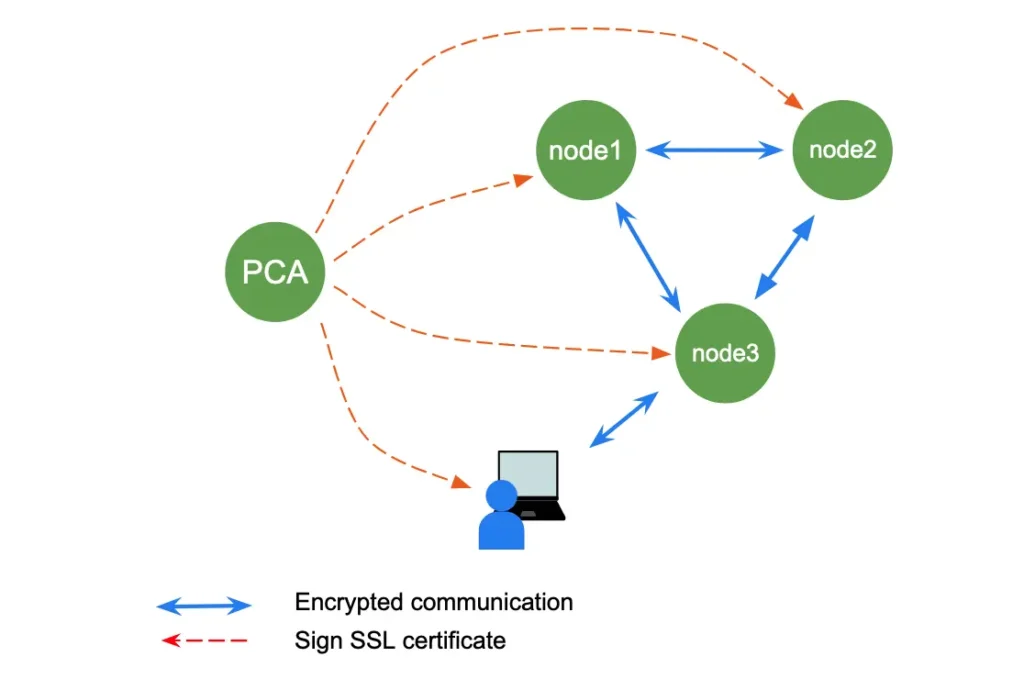
As shown above, the users outside the cloud can also acquire a signed certificate from the PCA. However, the users must manually create a secure tunnel into the cloud to apply for the certificates.
Within the internal network, requesting certificates will be automatic. It usually happens when an infrastructure component starts up. For example, when a Kafka broker starts up, it interacts with the PCA to acquire a certificate. Calabash, at runtime, will find the IP address of the PCA and send a certificate signing request on behalf of the broker.
In both cases, the users only need to specify the PCA names in the Calabash designer. They do not need to do define anything else.
For more advanced users, Calabash helps them deploy their own secure applications. Calabash offers a utility to set up TLS (SSL) environment. This utility is packed in a Docker image (datacanals/pca-client:latest) and available to anyone.
Using the Calabash PCA offers convenience and the tightest security. It also saves money. An alternative to Calabash PCA is to use the cloud platform-provided certificate signing feature. It charges by the number of certificate signing requests, which could run up to hundreds or even thousands of dollars per month. Using Calabash PCA, all you need to pay is the cost of a VM with the minimum configuration (about $26/month). There will be no per request charge since you own the certificate authority.
For more information about the Calabash PCA, please read The Use of Private Certificate Authority.
For more information about launching your app with Calabash PCA support, please refer to the article Running an App Securely both in the Cloud and On-Premise.
5. Calabash Helps Users Set up Kafka Systems
You can easily set up a Kafka system for your own learning, which runs on a single node without security. But to set up a Kafka system for production is not an easy task. You have to sort out many practical issues. The most obvious ones are:
- TLS (SSL) set-up
- Access Control List (or ACL) set-up
- Kafka-Connect set-up
Calabash takes these burdens from users 100%.
Users can use the Calabash web-based GUI to design a Kafka system by specifying a few simple properties. These include the number of zookeepers, brokers, and whether the user needs Kafka-Connect.
For security, the user specifies a PCA name, and the user creates a name for the superuser of the Kafka system.
The following is a screenshot of the Calabash GUI for defining a Kafka system.
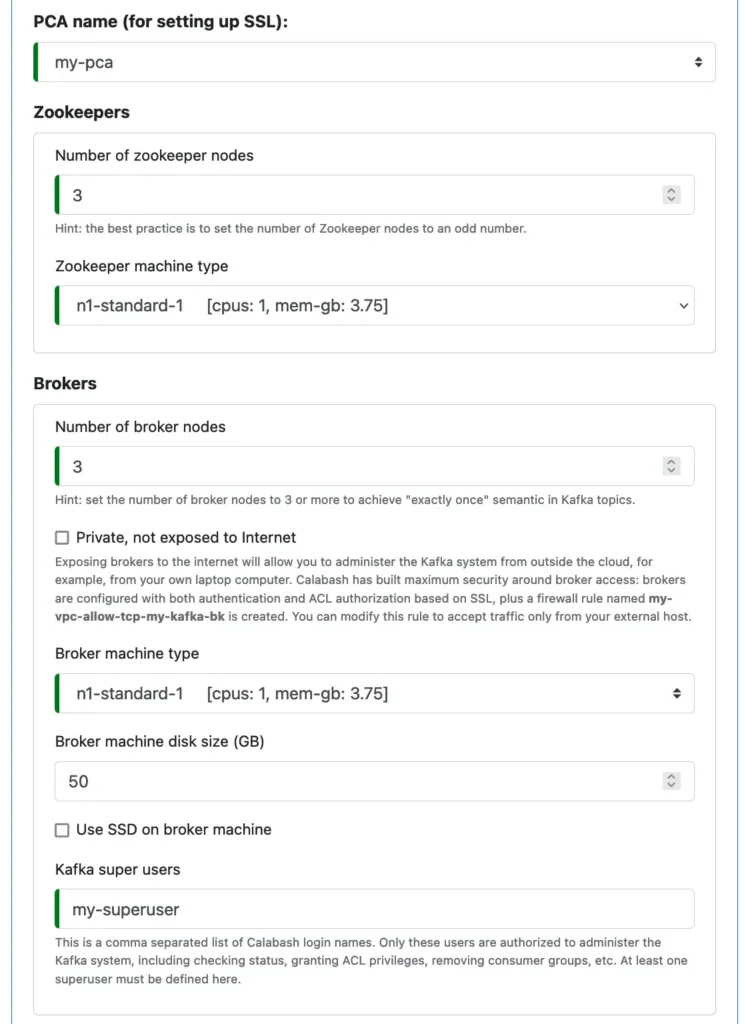
You can see from the above screenshot that hints are placed everywhere to help the user understand the properties. The help may also include information about the best practice.
After the design, the user uses the Calabash CLI to deploy the Kafka system to the cloud platform with just one command like this:
deploy i my-kafka
where “my-kafka” is the name for the Kafka system user just designed.
And that is all the user needs to do. Calabash will automatically generate TLS (SSL) certificates and various Kafka property files. It then starts all the nodes.
For a more detailed account of setting up Kafka systems, please refer to Setting up Secure Kafka with Fault-Tolerant Kafka-Connect.
6. Calabash Helps Users Manage Kafka Systems
A superuser of the Kafka system can use Calabash to deploy a “Kafka Client Environment” (KCE) to manage the Kafka system quite easily.
A KCE is just a configured directory containing credentials for accessing the Kafka system, plus some shell scripts for managing the system. It can be hosted on a VM or on the user’s PC. See below.
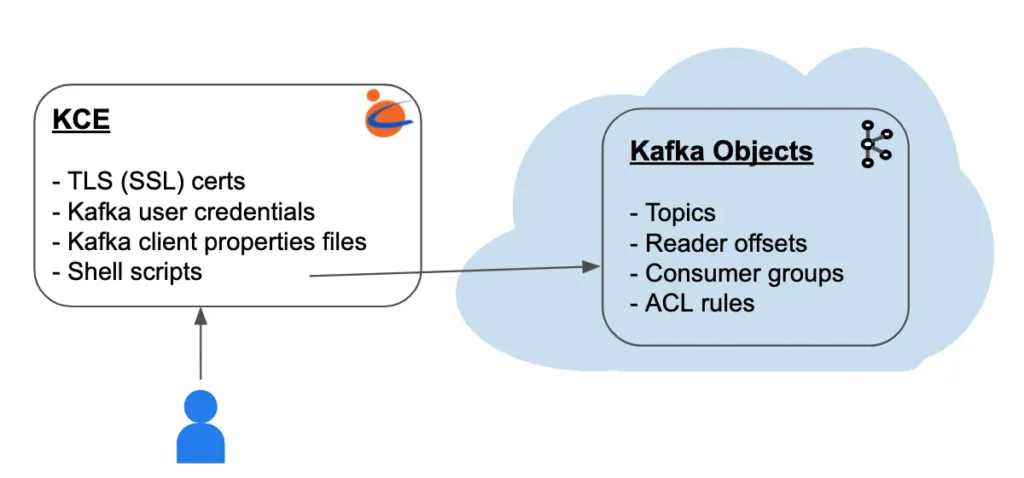
The Kafka user credentials are “baked” in the TLS (SSL) certificates. In a sense, the SSL certificates also serve the authentication purpose.
The Kafka superuser can use the scripts to list, describe, create, and delete topics. The user can also add ACL rules to grant permissions to other users. For example, allow some users to produce or consume data on a topic.
The reader offsets are essential for readers. Kafka keeps a “current offset” for each reader to avoid reading the same data twice. You may use the KCE scripts to manipulate this offset to force the reader to repeat or skip reading the source data.
Similarly, writers and data pipelines keep the so-called “consumer group offsets” to track their progress. You may use KCE scripts to manipulate these offsets to force a repeat or skip of the processing.
When the system runs smoothly, you will rarely need to manipulate these offsets. But you will most likely want to check their statuses. KCE offers scripts for doing that as well.
In summary, Calabash has collected a set of advanced scripts. These scripts are created through years of our fieldwork with Kafka. As of now, the functionalities in these scripts are not all available in other management tools.
To see what scripts are available, please refer to KCE Command Reference.
7. Calabash Helps Users Create Containerized Microservices/Websites
There will be little challenge to set up a web service on a stand-alone VM. But if you want to run it on a Kubernetes cluster, things become complicated. You must
- define and mount Kubernetes secrets
- define load balancer
- create TLS (SSL) certificates for the load balancer or each node
- define pods and autoscaling
- define Kubernetes deployment
These are error-prone tasks to complete by humans. You may have to go through several iterations to get the app running.
Calabash will take over these burdens from you 100%. All you need to do is create an “infrastructure object” with the type “microservice on K8s.” You specify some parameters and issue one command in Calabash CLI to deploy it to the cloud. And Calabash will generate all the configurations for you.
Calabash will also build a Docker container image on the fly if you do not have the image available yet.
For a detailed demo, please read the article Running an App Securely both in the Cloud and On-Premise.
8. Calabash Helps Users Cut Cloud Costs
Calabash offers users a “one button” set-up and tear-down. All the design blueprints are stored in the Calabash repository. To deploy an object, users type one “deploy” command in the Calabash CLI, and to remove it from the cloud, use the “undeploy” command. See below.
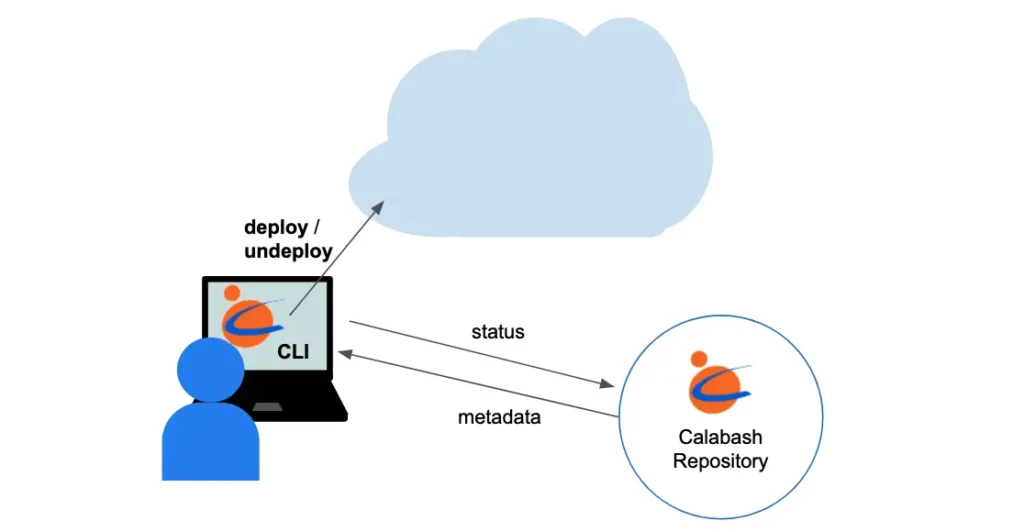
The metadata is stored in a Calabash repository (i.e., a database). Calabash does not delete the metadata after a successful undeploy command. This is different from the cloud platform console, which deletes both the resource and the metadata.
Using the persisted metadata, users can deploy/undeploy objects quickly. This can be the key to significant cost savings. The cloud platform charges by second, regardless of whether the resource is utilized. The quick deploy/undeploy feature amounts to an electric switch. Users will have the freedom to turn off “appliances” not in use.
9. Conclusions
The world is moving toward recording everything that happened in personal or business lives. Our current technology is useful but only to a small population of highly skilled developers. Calabash wants to change that.
In the movie “Total Recall,” the character played by Arnold Schwarzenegger experienced great pain, having lost his memory. He was willing to risk his life to get it back. So will be the technology world. Businesses will be hungry for the total recall because it can predict the future.
Calabash creates a usability layer over Kafka, making it easier to use. But the primary role does not have to be played by Kafka. Kafka is currently the best real-time messaging software. But in the future, if a more capable technology emerges, we will replace Kafka with the new one. Our users will continue to use Calabash in the same way as before. This is the essence of all software tools, i.e., creating insulations between users and complexity.