There is a compelling reason for saving data from Kafka: Kafka cannot keep your data forever. By default, Kafka holds it for seven days. After seven days, old data may be purged.
But the more often reason for saving data is users consider some Kafka topics contain valuable stuff. This is particularly true if the data have gone through a series of pipeline processing.
Saving data can be complicated. You will need developers skilled in using Kafka libraries. They must also be experts in accessing the target systems, for example, Google BigQuery. When the rubber touches the ground, they will face real-world issues from permission, quota, scheduling, etc.
All these challenges will disappear using Calabash, a tool for building data lakes in the cloud. Calabash will take the heavy lifting to generate code, configurations, and properties for the users. The users only need to specify what they need to save and where.
This article presents an example of saving Kafka data to Google BigQuery. Readers can see how easy it is to use Calabash.
If you are new to Kafka, please read a brief introduction in another article. Some general knowledge about Kafka will be helpful. But it does not have to be on the developer level since you will not write any code.
1. The Source, the Target, and Calabash Writers
The source in this demo is a Kafka topic named “students.” It contains data with both keys and values of strings. Every record in a Kafka topic is a key-value pair.
The target is a Google BigQuery table named “students.” It is in a dataset named “demo.” To simplify things, we will have only two fields in this table. Their names are “key” and “value.” Both are of string type. The plan is to offload data from the Kafka topic to the BigQuery table verbatim.
We must create the BigQuery table before we start the writer process. The following screenshot shows the structure of this table in Google Cloud Platform.
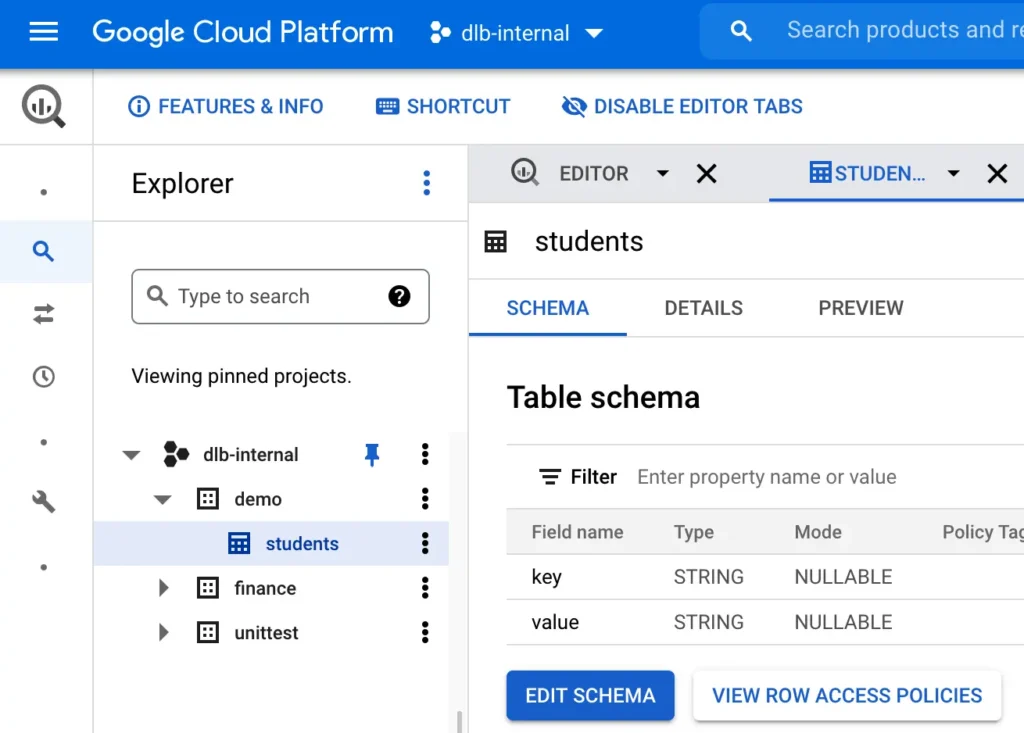
In the next section, we will design the writer using Calabash GUI. And in section 3, we will deploy it to the cloud and start running it using Calabash CLI.
Now a few words about Calabash writers in general. Calabash offers the following types of writers for offloading data from Kafka in real-time.
- CSV file writer
- JSON file writer
- Avro file writer
- Parquet file writer
- JDBC table writer
- Google BigQuery writer
- API target writer
All the Calabash writers are implemented by Kafka sink connectors.
The above list covers the most frequent needs in reality. But it is impossible to cover all the grounds. If what you need is not on the available writers’ list, you can contract Data Canals to create a custom writer for you.
2. Design the Writer
The sequence of work is as follows. We first design the “blueprint” (or metadata) of a writer. Then download the Calabash CLI, and use it to deploy the design to the cloud. The design phase does not require writing code. The Calabash CLI will generate code for us during the deployment. In addition to the code-gen, the CLI also generates configurations and property files.
To design the writer, use a browser, go to the Calabash GUI at https://calabash.datacanals.com. Log in, and start the create writer form. See below.
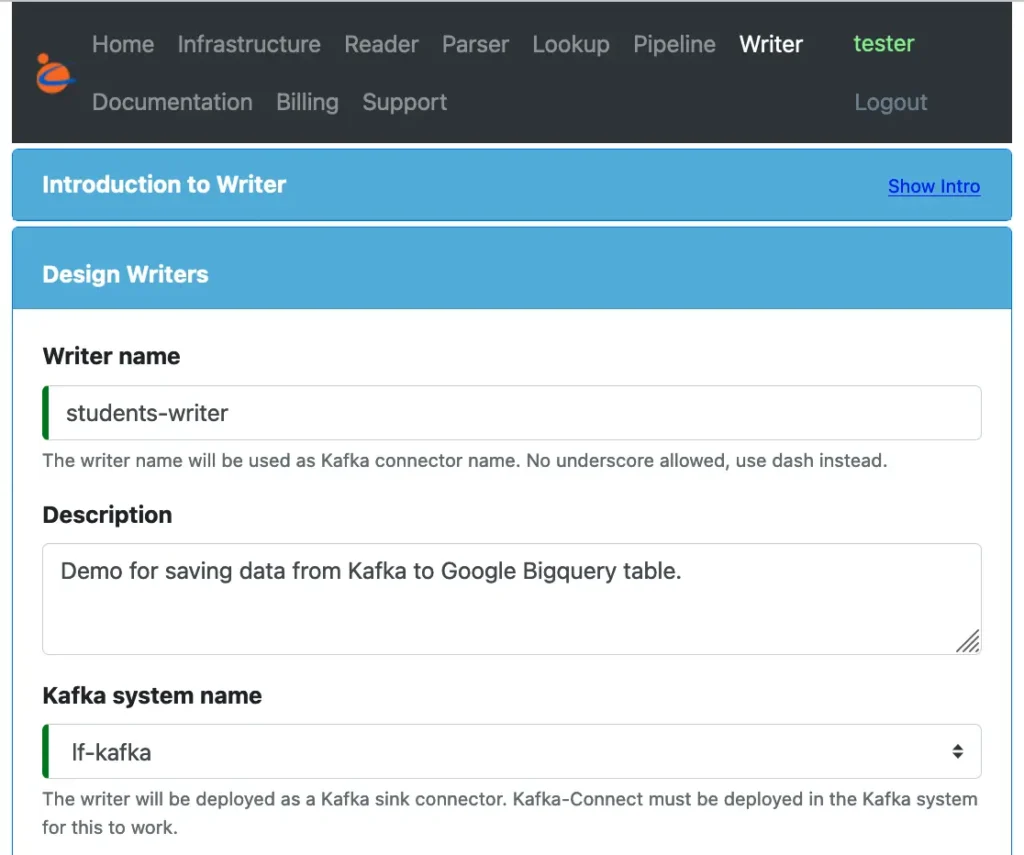
We need to give a name to the writer. This name will be the Kafka connector name at runtime. Make sure it does not conflict with currently running readers or writers.
Add some description for our reference and select the Kafka system. The Kafka system is another blueprint designed using Calabash. Because our focus in this article is the writer, we will omit the details creating Kafka systems in Calabash.
Next, we need to describe the source Kafka topic.
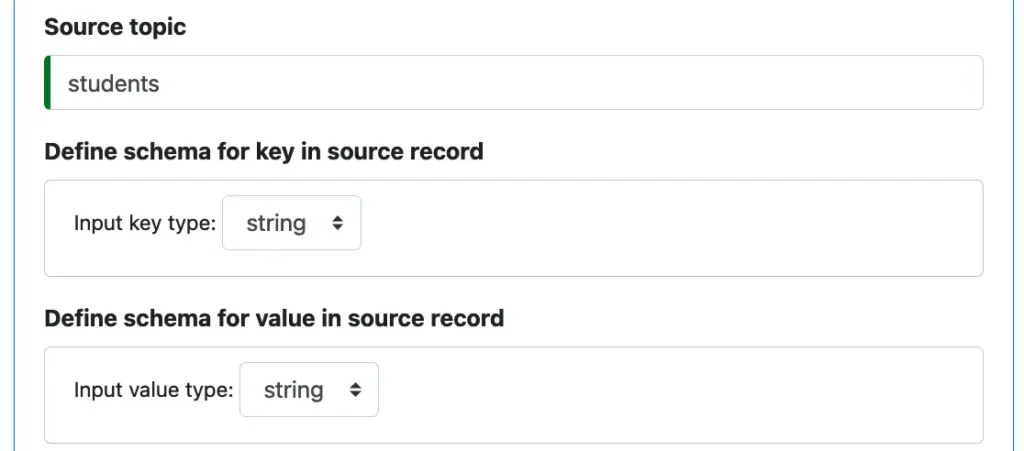
Both key and value in a source record are strings. Nothing special in this screenshot. However, Calabash allows you to offload data with arbitrary structure.
Another option in the drop-down lists for the types is “record.” (Not shown in this screenshot.) Once selected, you can build a schema for the record type. The feature for processing arbitrary data types is a big subject in its own right. To stay focused on writers, we will sidestep it. But suffice it to say that Calabash helps you save any data.
Next, we describe the Google BigQuery target.
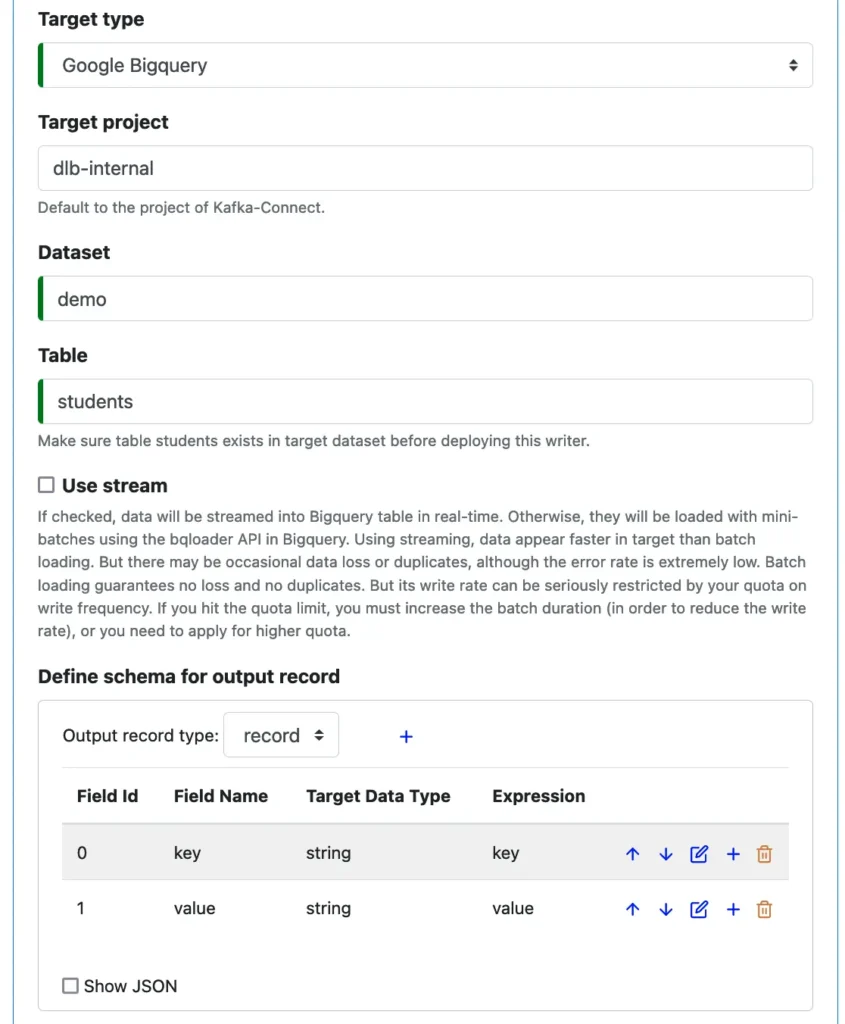
From a list of supported writers, we have selected “Google Bigquery.” And we enter the usual information about the target BigQuery table.
Google BigQuery supports two loading methods: the batch method and the streaming method. As shown in the screenshot, we opt for the batch method.
Same as defining source schema, we can describe the schema about the target table. The interesting thing to note in the above screenshot is the “Expression” column. It defines how the output field is mapped to the source field. The “key” and “value” in the “Expression” column mean the source key and value, respectively.
If, however, our source value was a record, and we wanted to map the target value to a field in the source, we could enter “value.field” as the expression. You actually do not type this expression. Calabash GUI will figure out all the valid ones, and you just select from the drop-down list.
Finally, there are some miscellaneous properties regarding the runtime behavior of the Kafka connector.
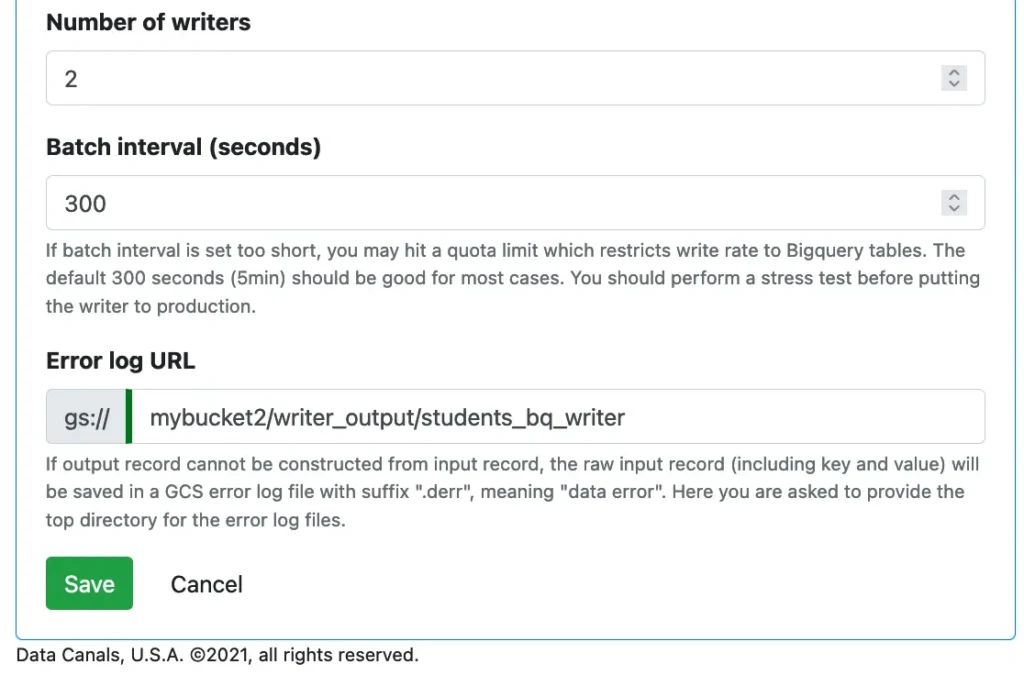
Kafka-Connect can launch multiple workers to increase the throughput. We can define this parallelism by setting the number of writers.
We are restricted by the BigQuery input rate quota. This quota applies if we choose the batch load method. Therefore, we set a batch interval to 300 seconds to reduce the loading rate.
There are lots of hints placed in the designer. They provide information about gotchas and best practices.
The writer can also save failed source records to a cloud storage location. For the batch loading method, its writing-to-BigQuery part is transactional. So failures will all be from reading the Kafka topic. But for the streaming method, errors could be from anywhere. Defining the error log location is required.
When the “Save” button is enabled, we have entered all the required information about our new writer. Click the “Save” button to conclude the design of the writer.
3. Deploy the Writer
There are some prerequisites for running writers. These are
- deploy a Private Certificate Authority (PCA) to enable TLS (SSL) communications,
- deploy a Kafka system,
- deploy a Kubernetes cluster for Kafka-Connect,
- deploy Kafka-Connect, which runs on the Kubernetes cluster,
- set up TLS (SSL) on your PC so that you have the credentials to access Kafka-Connect,
- deploy a Kafka Client Environment (KCE) to monitor and manage the writer.
These can all be designed and deployed using Calabash. Because the focus of this article is on writers, we will skip the details about them.
To deploy the writer, we use the Calabash CLI. The tarball of the Calabash CLI can be downloaded from the Data Canal website. It does not require installation. Just unpack it, and it is ready for use.
To launch the Calabash CLI, go to the directory where the Calabash CLI is unpacked and issue “bin/calabash.sh.” See the following transcript.
% bin/calabash.sh Calabash CLI, version 3.0.0 Data Canals, 2022. All rights reserved. Calabash > connect tester Password: Connected. Calabash (tester)> use ds lake_finance Current ds set to lake_finance Calabash (tester:lake_finance)>
The above example shows we log in to the Calabash repository as user “tester.” Then we set the context to a data system we have designed. The data system name is “lake_finance.” Our writer is contained in this data system. The prompt has changed to display the connected user name and the current data system.
We can list all writers in this system using the “list w” command:
Calabash (tester:lake_finance)> list w
Writer Name Topic Description Type Status
--------------- --------------- ------------------------------ ------------------------------ ------------------------------
students-writer students Demo for saving data from Kafk Google Bigquery >>> Created at 11/30/2021, 5:
a to Google Bigquery table. 47:24 PM
The list contains just one writer in this example.
We are now ready to deploy this writer. To do that, issue the “deploy w” command.
Calabash (tester:lake_finance)> deploy w students-writer Deploy to cloud? [y] Deployed to Kafka-Connect @ https://34.132.10.172:8083 Calabash (tester:lake_finance)>
Calabash supports writers both in cloud and on-premise. In the above example, we hit the RETURN key to take the default to go for the cloud.
If there are no errors, the writer is successfully deployed to Kafka, and it has started running.
We have just deployed a real-time data offloading process without writing a single line of code. Neither did we write any configuration or property files.
4. Monitor the Writer
There are several ways to check the health of the writer. The foremost is to see if we have the data written to the target. In our example, this target is a Google BigQuery table.
Go to the GCP console and issue a query to the table. We see the following result:
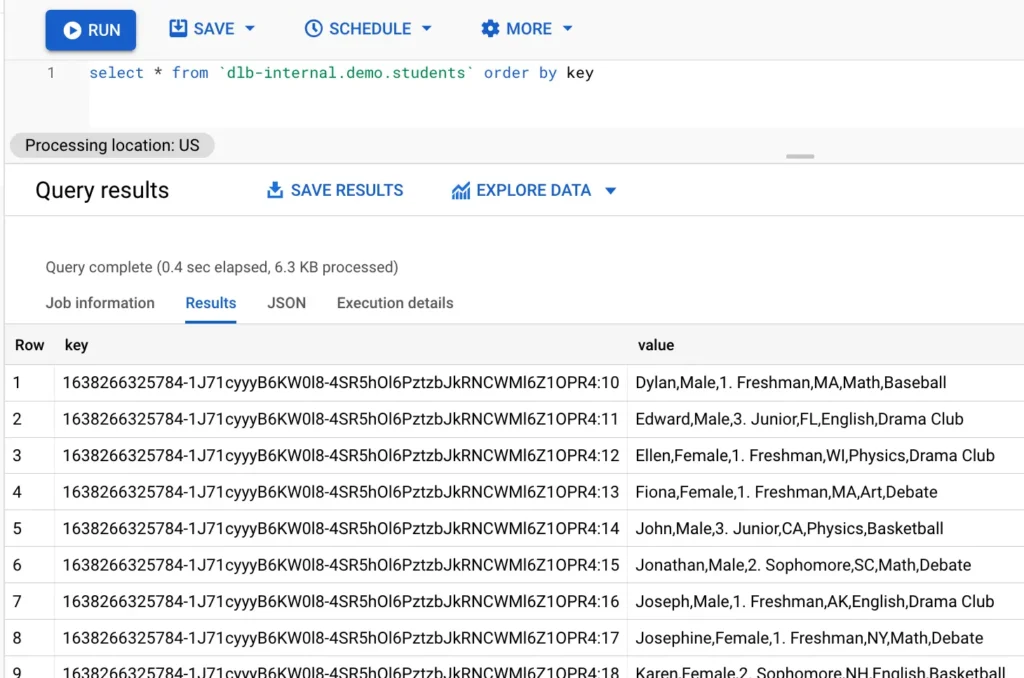
The fact that we are getting some data in the table is a good sign that the data flow to the target is working. But we still do not know if there were erroneous data because they could not make it to the table. To check that, we must examine the error log. According to the writer design, the error log is in the cloud storage at this location: gs://mybucket2/writer_output/students_bq_writer.
In this example, we do not see any errors. But if we did hit some, the error log would contain something similar to the following.
[{"error":"Quota exceeded.","value":"Anna,Female,1. Freshman,NC,English,Basketball","key":"1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:4","ts":"20211129_181935_285"},
{"error":"Quota exceeded.","value":"Benjamin,Male,4. Senior,WI,English,Basketball","key":"1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:6","ts":"20211129_182900_54"},
{"error":"Quota exceeded.","value":"Carrie,Female,3. Junior,NE,English,Track & Field","key":"1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:8","ts":"20211129_183567_124"},
...
]
The error log contains a list of JSON records, each for a problematic source record. We can see the values and keys of the source record and the error messages.
What if Calabash hits an error writing the error log? To make sure that did not happen, we must check the Kafka-Connect “pod log” in the Kubernetes cluster where it is running. That will require some skills about Kubernetes from the users. We will omit the how-to on that, but suffice it to say that you should not see any exception in the Kubernetes log for the Kafka-Connect.
If you see any exceptions, please read the error message carefully. Common runtime errors include
- No permission to access Google storage,
- The storage bucket does not exist
To fix the issue, first, undeploy the writer using Calabash CLI with the undeploy command:
Calabash (tester:lake_finance)> undeploy w students-writer Is the writer in cloud? [y] Undeployed.
Then make necessary changes and deploy the writer again.
You can deploy and undeploy the writer any time without affecting the writer’s result because Kafka remembers the success offset in the source topic.
Here is another way to monitor a writer’s health. We can check the success offset using the KCE. The KCE (Kafka Client Environment) is provided by Calabash for monitoring and managing Kafka systems.
A KCE is, in fact, a directory you can deploy (using Calabash CLI) either to your PC or a container in the cloud. It contains all the credentials and property files for accessing the Kafka system you selected. We will omit more details about the KCE because it is not the focus of this article.
In the “bin” directory in a KCE, you can find all shell scripts for managing the Kafka system. One of them is the “list_consumer_groups.sh” script. You can use it to find the “consumer group” automatically created for the writer.
root@bd9603609b09:/app/bin# ./list_consumer_groups.sh jdoe connect-students-writer
In the above example, “jdoe” is the superuser of the Kafka system. Only a superuser can check this metadata in Kafka.
Then we use another script to see the details of the consumer group named “connect-students-writer.”
root@bd9603609b09:/app/bin# ./desc_consumer_group.sh jdoe connect-students-writer GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID connect-students-writer students 0 32 32 0 connector-consumer-students-writer-0-1a2e4204-a760-4e28-a491-b6c3c6523f2a /34.118.10.135 connector-consumer-students-writer-0 connect-students-writer students 1 32 32 0 connector-consumer-students-writer-1-33c8a367-151c-4e78-907b-e044b1392a40 /34.118.10.135 connector-consumer-students-writer-1
The “LAG” is the first stat we want to check. If the writer can keep up with the data flow in the source topic, the lag should be zero or hold constant. Another important stat is the “CURRENT-OFFSET,” which is the success offset, meaning records with (offset < CURRENT-OFFSET) have been loaded.
5. Manage the Writer
There are scripts in KCE to pause/resume the writer. We can also rewind the writer using the “set_consumer_offset.sh.”
Suppose, for whatever reasons, we want to resend the last two records to BigQuery again, we can do the following:
root@bd9603609b09:/app/bin# ./set_consumer_offset.sh jdoe students connect-students-writer 30 GROUP TOPIC PARTITION NEW-OFFSET connect-students-writer students 0 30 connect-students-writer students 1 30
With this command, the success offset is rewound back to 30. Records at offset 30 and 31 will be resent.
Special note: the writer must be undeployed before issuing the above command. Kafka does not allow modifying the offsets if the connector is still active.
After the offsets are changed, redeploy the writer using Calabash CLI. You will see two new records appear in the BigQuery table. They are duplicates of two previous records.
Finally, we cannot set offsets higher than their current values, i.e., we cannot skip future records.
6. Conclusions
A picture is worth a thousand words. The following diagram summarizes what we have demonstrated in this article.
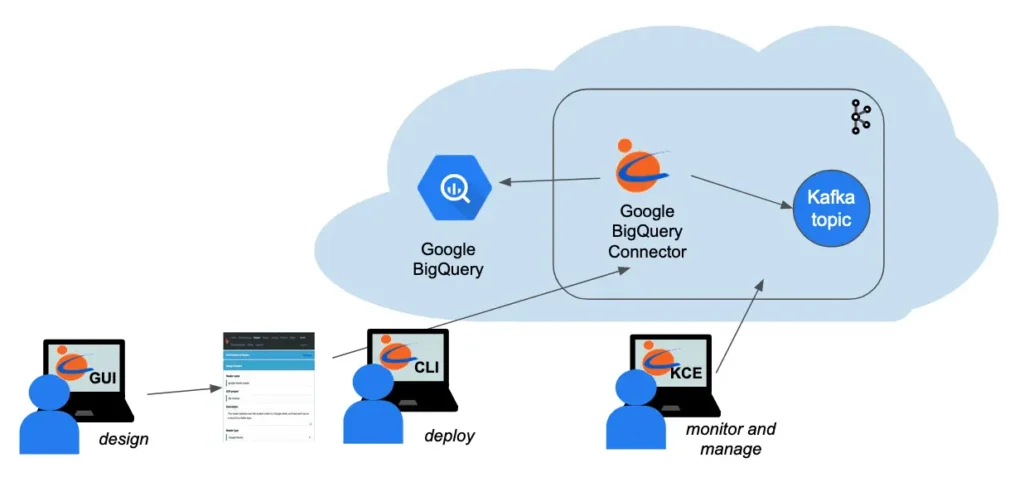
You, the user, design the writer using Calabash GUI. Then you can issue one Calabash CLI command to deploy it to the cloud. In the entire process, you never write code, but the deployment process will automatically generate code, configuration, and security setup for you. While the writer is running, you can use Calabash KCE to monitor and manage it.
Kafka has created an open platform for users to write and deploy connectors suitable for the users’ own situations. This is both good and bad. It is good that users will have the freedom to deal with their specific problems. But it requires advanced skills to write the connectors. Some development teams decided to stay away from Kafka-Connect due to its complexity. Unfortunately, they have missed a great technology, and they cannot avoid reinventing wheels.
Calabash has created a set of ready-to-use Kafka connectors that cover a great spectrum in the business world. Users can design their writers by selecting from the Calabash writers.
If what you need is not on the list, Data Canals also offers professional services. We will develop readers to your specification and provide follow-up maintenance service contracts. If you are interested in getting help from Data Canals, please send us an inquiry at the Professional Service Inquiry page.
7. Further Reading
Calabash can also help you create readers similarly to writers. Readers pull data from various sources into Kafka topics. For an example of that use case, please check the article Collect Data to Kafka without Writing Code.
Users may use Kafka topics as the data gathering points for heterogeneous applications. To that end, you would only need readers and writers. However, that functionality is perhaps less than half of what Kafka can do.
You may also process the data in Kafka by creating data pipelines in Kafka Streams. Calabash can also help users create and manage data pipelines without writing code. For an introduction with a concrete example, please read A Simple GUI for Kafka Streams.
For a summary of all use cases of Calabash, please refer to the article Summary of Use Cases.
For product information about Calabash, please visit the Data Canals homepage.
The Calabash documentation site contains all the official articles from Calabash. The documentation includes extensive tutorials that lead readers in a step-by-step learning process.
For theoretical-minded readers, we recommend the introductory article What is Data Lake. You will understand that Calabash has a much more ambitious goal than helping users use Kafka.
A data lake is vital to any business if it wants to “examine” itself. Socrates must be pleased to see the proliferation of data lakes.