Socrates once said, “The unexamined life is not worth living.”
No doubt, we humans all want to make lives meaningful. We want to learn from the past, better ourselves, and find a guide for the future. But how to “examine” lives is a complicated matter. We develop this skill throughout our lives.
The business world uses “analyze” instead of “examine.” But the moral all holds true. Our data analysis technologies improve every year. However, one problem will ruin everything, viz., the problem of not having any data.
The only solution to this problem is to avoid it. We must pay attention to collecting data for analysis. In fact, we should collect all data we encounter, regardless of whether they are “important” or not. Great insights are often hidden in a large amount of seemingly unimportant events. Advanced data analysis algorithms may not be available right now. But we cannot wait for their birth before starting to collect data.
The most technically sound software so far for data collection in real-time is Apache Kafka. But it has a steep learning curve. Even to experienced developers, it is not a simple task to design and deploy Kafka processes. Therefore, Kafka is often dubbed “enterprise” grade software, leaving a large population of businesses without a viable data collection tool.
This picture will change with an online software tool called “Calabash.” Calabash creates a GUI interface to Kafka, Kafka-Connect, and Kafka Streams, the three major components in the Kafka bundle. Users of Calabash do not need to know much about Kafka, but they can create
- real-time data collection processes, which collect data from anywhere into Kafka,
- real-time data processing pipelines, which process data in arbitrary ways,
- real-time data persistence processes, which save data from Kafka to anywhere.
Most importantly, users accomplish the above without having to write code. They use GUI to describe what they need, and Calabash generates code, configurations, and commands/REST requests for them. The learning curve becomes almost flat.
This article presents an example of collecting data from Google Sheets to Kafka in real-time. It demonstrates how easy it is to do data collection using Calabash. You may also read two companion articles showcasing data processing and data persistence.
Before presenting the case, we will first go through a brief introduction to Kafka. You may skip this introduction if you are already familiar with Kafka, Kafka-Connect, and Kafka Streams.
1. What Is Kafka?
Apache Kafka is open-source software. Its core engine is designed for
- storing data in memory-bound queues, called “topics,”
- coordinating distributed producers and consumers of these queues.
The core engine lays the foundation for real-time data service because first, it offers ultra-high throughput, and second, it coordinates distributed producers and consumers. Both are engineering feats.
On top of the core engine, we have an essential service for getting data in and out of Kafka. This is called “Kafka-Connect.” But don’t expect Kafka-Connect to give you a truck-load of input/output libraries. It actually offers none.
What Kafka-Connect provides is a platform to run data input/output programs called “connectors” written by the users or third parties. The rationale goes something like this. Since the users have the best knowledge about their data, they should write code to extract or save them. Kafka-Connect will load users’ connector code and coordinate the running.
Over many years, there has been an ecosystem for Kafka connectors. You may free download or purchase them from various sources. Place them in the correct locations, then Kafka-Connect will automatically detect and load them.
If nothing suits your need, you must write your own connectors or contract someone to do so. There are two types of connectors you can develop.
- Source connector: for getting data from anywhere to Kafka topics.
- Sink connector: for writing data from Kafka topics to anywhere else.
You may market and sell your connectors and contribute to the ecosystem if you think they are widely applicable.
Kafka is not just a temporary holding tank. It is actually a powerful processing engine. Once data are in Kafka topics, you may run your data processing code to modify the data. These processes are called “pipelines.” A pipeline always starts from a Kafka topic and ends at another one. In between, there is a sequence of processing stages called “processors.”
To write the pipeline code, we must use the Kafka Streams library. This library allows us to define the topology of the data flow and add the processing code for each processor. In the processing code, the users can apply their knowledge about the data and implement transforms to meet business requirements. The business requirements can vary widely in the real world.
Each pipeline is a stand-alone application. It could be run in a single node or in a Kubernetes cluster. Running it in a Kubernetes cluster is the best practice since it offers fault-tolerance and auto-scaling.
Finally, why is Kafka the best? First, Kafka has the highest throughput among similar software. It is twice better than the next rival (Apache Pulsar). And for real-time systems, it is the throughput that is important. High throughput ensures we can always keep up with real-world events and never suffer from data loss. In reality, we must also factor in the possibility of volume spikes and always go with the system with the highest throughput capacity.
Second, Kafka offers “exactly once” processing semantic. It implies no loss and no duplicate of the processed data. It is another engineering feat in the distributed environment. In contrast, Pulsar only supports a “practical” exactly-once semantic. In most cases, it may be ok, but there is no 100% guarantee, particularly when there is a high error rate in the system.
2. The Source Data and the Requirement
Google Sheets is an online service for creating spreadsheets. It is freely available to the public and has gained wide popularity. Many businesses rely on Google Sheets to share data among remote workers.
Suppose we are keeping a class roster of students enrolled in a college. The spreadsheet can be found here:
A portion of this sheet is shown below for readers’ convenience.
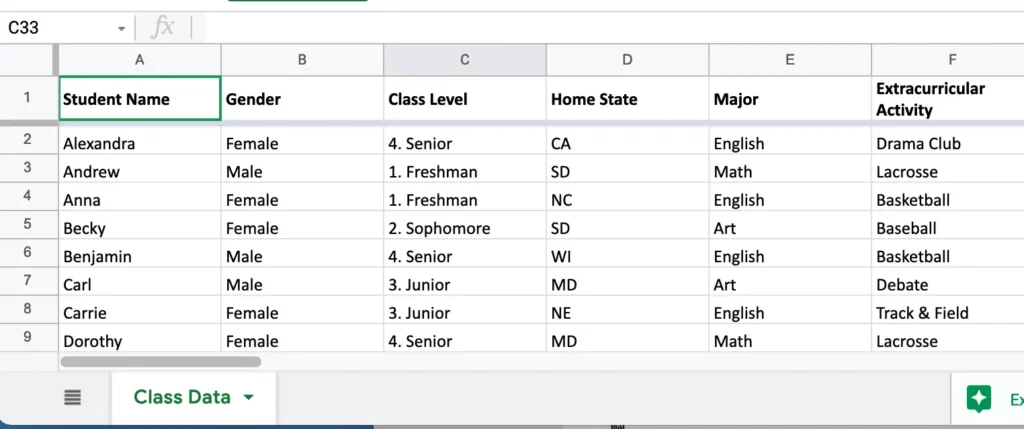
We want to load data in this sheet to a Kafka topic. Each line, except the title, is a record.
We will append new students to this sheet, and as we enter the data, we expect Kafka to instantly load new records.
After a while, say at the beginning of a new semester, we want to start over. We will empty this sheet. Kafka should know where the new data starts.
3. Design of a Reader
Calabash offers an online designer for users to create “readers.” A reader is a real-time data watcher and loader on a source. In most cases, a reader is implemented by a Kafka connector.
Calabash offers several built-in connectors.
- Text file reader
- Binary file reader
- Avro file reader
- Parquet file reader
- Microsoft Excel file reader
- Google Sheets reader
- JDBC query reader
- API service reader
In this example, we will use the “Google Sheets reader.”
We create a reader using the create-user form in Calabash GUI and enter some simple properties. See the following screenshot.
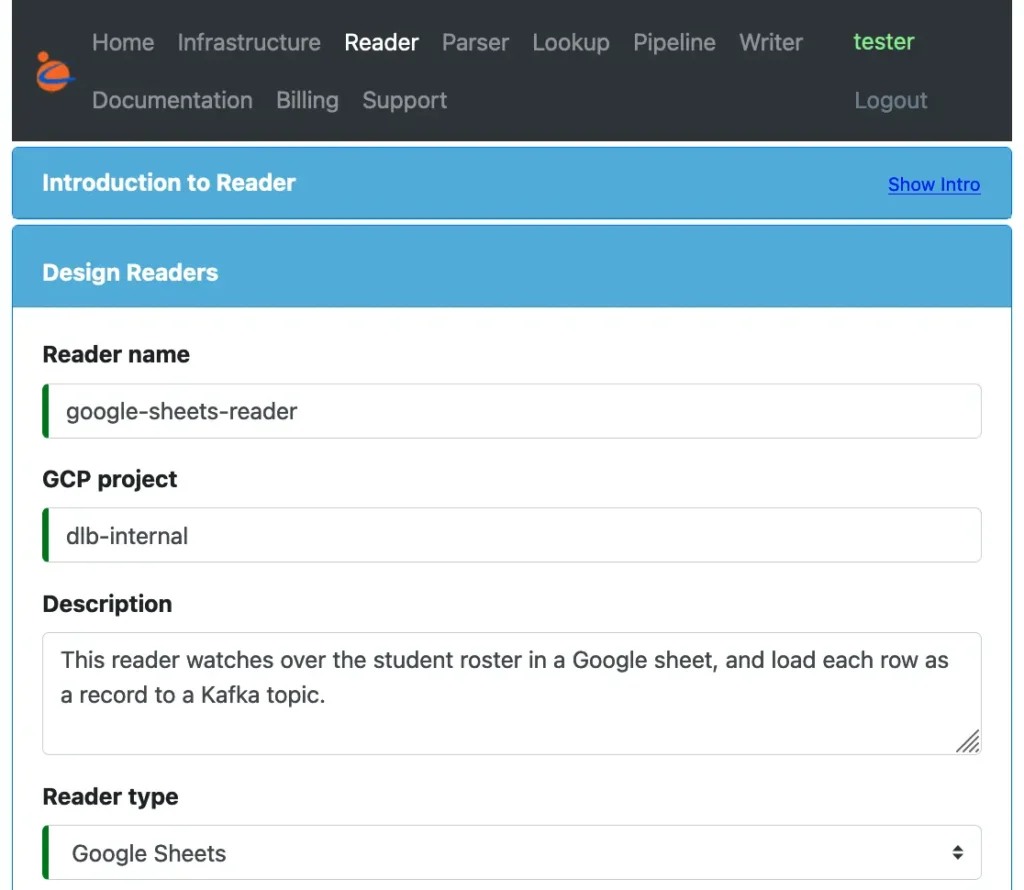
In the first part of this form, we give a name for the reader. This will be the Kafka connector name. Then add some optional descriptions. And we set the “Reader type” to “Google Sheets.”
After that, we set some properties describing the target Kafka topic.

In the drop-down list for “Kafka system name,” select the Kafka system you have created. (In this article, we will not cover the Kafka system creation.) Calabash allows you to design various infrastructure objects. A Kafka system is one of them. Once you have created a Kafka system, its name will appear in the above drop-down list.
In this Kafka system, we want to load data to a topic named “students.” This topic may not exist in the Kafka system. If so, we must remember to create it before running the reader. The GUI gives you some practical hints at various places.
The “Batch size” is the number of records the reader collects before sending them to Kafka topic. Adjusting the batch size will affect record latency.
That’s all for the target. In the last part of the form, we specify properties for the data source.
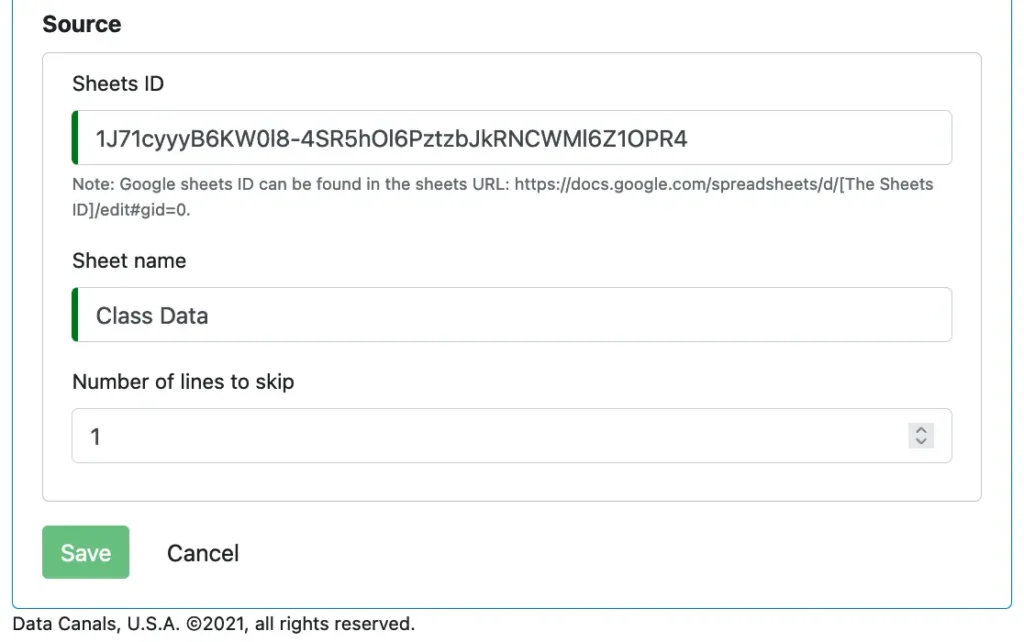
Our source is a Google sheet. We need to enter its id and the sheet name. The id can be found from the URL of the sheet.
Click on “Save” and we have completed the design of a reader.
4. Deploy a Reader to a Kafka System
There are some prerequisites for running readers. These are
- deploy a Private Certificate Authority (PCA) to enable TLS (SSL) communications,
- deploy a Kafka system,
- deploy a Kubernetes cluster for Kafka-Connect,
- deploy Kafka-Connect that runs on the Kubernetes cluster,
- set up TLS (SSL) on your PC so that you have the credentials to access Kafka-Connect,
- deploy a Kafka Client Environment (KCE) to monitor and manage the reader.
These can all be designed and deployed using Calabash. Because the focus of this article is on readers, we will skip the details about them.
To deploy our reader, we use the Calabash CLI. The tarball of the Calabash CLI can be downloaded from the Data Canal website. It does not require installation. Just unpack it, and it is ready for use.
To launch the Calabash CLI, go to the directory where the Calabash CLI is unpacked and issue “bin/calabash.sh.” See the following transcript.
% bin/calabash.sh Calabash CLI, version 3.0.0 Data Canals, 2022. All rights reserved. Calabash > connect tester Password: Connected. Calabash (tester)> use ds lake_finance Current ds set to lake_finance Calabash (tester:lake_finance)>
The above example shows we log in to the Calabash repository as user “tester.” Then we set the context to a data system we have designed. The data system name is “lake_finance.” Our reader is contained in this data system. The prompt changes to display the connected user name and the data system context.
We can list all readers in this system using the “list r” command:
Calabash (tester:lake_finance)> list r
Reader Name Project Description Type Status
--------------- --------------- ------------------------------ ------------------------------ ------------------------------
google-sheets-r dlb-internal This reader watches over the s Google Sheets >>> Updated at 4:33 PM11/29/20
eader tudent roster in a Google shee 21, 10:27:36 PM
t, and load each row as a reco
rd to a Kafka topic.
The list contains just one reader in this example.
We are now ready to deploy this reader. To do that, issue the “deploy r” command.
Calabash (tester:lake_finance)> deploy r google-sheets-reader Deploy to cloud? [y]: Deployed to Kafka-Connect @ https://34.132.10.172:8083 Calabash (tester:lake_finance)>
The CLI can deploy a reader to the cloud platform or on-premise. In the above example, we hit the RETURN key to take the default, i.e., to go for the cloud.
If there are no errors, the reader is successfully deployed to Kafka, and it has started running.
We have just deployed a real-time data collection process without writing a single line of code. Neither did we write any configuration files or property files.
5. Monitor the Reader
How do we know if the deployed reader is working fine? Has it hit any issues? How do I manage the reader, such as starting/stopping it? Calabash offers an environment for doing all these. This environment is called “Kafka Client Environment” or KCE.
A KCE is a directory you can deploy (using Calabash CLI) either to your PC or a container in the cloud. It contains all the credentials and property files for accessing the Kafka system you selected. We will omit more details about the KCE because it is not the focus of this article.
In the “bin” directory in a KCE, you can find all shell scripts for managing the Kafka system. One of them is the “consume.sh” script. You can use it to check the content of a topic.
The following transcript shows how to use this script to check if our reader has loaded any data to the topic “students.” (Note: the argument “april” is the name of a consumer user, and “g0” is a name for “consumer group.”)
root@4d27a8c939da:/app/bin# ./consume.sh april students g0 "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:4"|"Anna,Female,1. Freshman,NC,English,Basketball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:6"|"Benjamin,Male,4. Senior,WI,English,Basketball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:8"|"Carrie,Female,3. Junior,NE,English,Track & Field" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:9"|"Dorothy,Female,4. Senior,MD,Math,Lacrosse" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:11"|"Edward,Male,3. Junior,FL,English,Drama Club" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:14"|"John,Male,3. Junior,CA,Physics,Basketball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:15"|"Jonathan,Male,2. Sophomore,SC,Math,Debate" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:16"|"Joseph,Male,1. Freshman,AK,English,Drama Club" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:19"|"Kevin,Male,2. Sophomore,NE,Physics,Drama Club" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:20"|"Lisa,Female,3. Junior,SC,Art,Lacrosse" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:21"|"Mary,Female,2. Sophomore,AK,Physics,Track & Field" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:24"|"Olivia,Female,4. Senior,NC,Physics,Track & Field" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:28"|"Sean,Male,1. Freshman,NH,Physics,Track & Field" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:30"|"Thomas,Male,2. Sophomore,RI,Art,Lacrosse" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:31"|"Will,Male,4. Senior,FL,Math,Debate" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:2"|"Alexandra,Female,4. Senior,CA,English,Drama Club" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:3"|"Andrew,Male,1. Freshman,SD,Math,Lacrosse" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:5"|"Becky,Female,2. Sophomore,SD,Art,Baseball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:7"|"Carl,Male,3. Junior,MD,Art,Debate" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:10"|"Dylan,Male,1. Freshman,MA,Math,Baseball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:12"|"Ellen,Female,1. Freshman,WI,Physics,Drama Club" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:13"|"Fiona,Female,1. Freshman,MA,Art,Debate" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:17"|"Josephine,Female,1. Freshman,NY,Math,Debate" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:18"|"Karen,Female,2. Sophomore,NH,English,Basketball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:22"|"Maureen,Female,1. Freshman,CA,Physics,Basketball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:23"|"Nick,Male,4. Senior,NY,Art,Baseball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:25"|"Pamela,Female,3. Junior,RI,Math,Baseball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:26"|"Patrick,Male,1. Freshman,NY,Art,Lacrosse" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:27"|"Robert,Male,1. Freshman,CA,English,Track & Field" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:29"|"Stacy,Female,1. Freshman,NY,Math,Baseball"
In a Kafka topic, every record is a key-value pair. The output of the “consume.sh” script displays all of them, one per line. On each line, a vertical bar separates the key from the value. As you can see from the above, values are the CSV lines from the Google Sheets.
We may add more lines in the Google Sheets, and the new records should show up in the “consume.sh” output momentarily.
In case you do not see the data you expect, you may check the Kafka-Connect “pod log” in the Kubernetes cluster where it is running. That will require some skills about Kubernetes from the users. We will omit the how-to on that, but suffice it to say that you should not see any exception in the Kubernetes log for the Kafka-Connect.
If you see any exceptions, please read the error message carefully. Common runtime errors include
- No permission to access Google sheet,
- Code 404: cannot find Google sheet,
- Not authorized to access topic.
To fix the issue, first, undeploy the reader using Calabash CLI with the undeploy command:
Calabash (tester:lake_finance)> undeploy r google-sheets-reader Is the reader in cloud? [y]: Undeployed.
Then make necessary changes and deploy the reader again.
You can deploy and undeploy the reader any time without affecting the reader’s result because Kafka remembers the success offset in the Google Sheet.
6. Manage the Reader
Calabash KCE offers scripts that cover all you need to manage a reader, including suspend/resume. Here we demonstrate an advanced operation that “rewinds/fast-forwards” the reader.
Let’s go back to our example of the student roster. Suppose we want to empty the Google Sheets content at the beginning of a new semester. We want to add new students to an empty sheet.
If we truncate the sheet, we will see new students are not loaded to the Kafka topic. This is because Kafka records the last successful row number in the sheet. It will not load data below this offset.
We can see this metadata in Kafka using the “list_reader_offset.sh” script. (Note: in the example, the argument “jdoe” is the name of a superuser in the Kafka system.)
root@bd9603609b09:/app/bin# ./list_reader_offsets.sh jdoe
Key (129 bytes): ["google-sheets-reader",{"sheet_id":"1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4","topic":"students","sheet_name":"Class Data"}]
Value (10 bytes): {"rid":32}
Timestamp: 1638266334632
Partition: 1
Offset: 0
The output shows one metadata entry with a lot of information. The key matches our reader, and the value indicates the “rid” (meaning “row id”) is at 32. This is the next row the reader is waiting to read. Any row id below 32 is ignored. This “high water mark” is why new data are not accepted after emptying the sheet.
Calabash KCE allows us to modify the offset value in the metadata. The following is an example to change the above “rid” to 1.
root@bd9603609b09:/app/bin# ./set_reader_offset.sh jdoe 1 \
'["google-sheets-reader",{"sheet_id":"1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4","topic":"students","sheet_name":"Class Data"}]' \
'{"rid":1}'
This command appears wordy but actually quite simple. The first two arguments are the superuser name (“jdoe”) and the partition number for the metadata entry (1 according to the “list_reader_offsets.sh” output).
Then we copy the long metadata key from the “list_reader_offsets.sh” output. But make sure it is enclosed in single quotes. Finally, we put the new value we wish to set, i.e. {“rid”:1}. Note that it is also enclosed in single quotes to avoid any misinterpretation in the shell.
After this command, the “rid” is set to 1, and our reader will start to load from offset 1 again.
In fact, you may set the “rid” to any value, even higher than 32 in this example. This will have the effect of skipping some rows from the future.
Using the “list_reader_offsets.sh” and the companion “set_reader_offset.sh,” we can easily rewind a reader or fast-forward it.
7. Conclusion
A picture is worth a thousand words. The following diagram summarizes what we have demonstrated in this article.
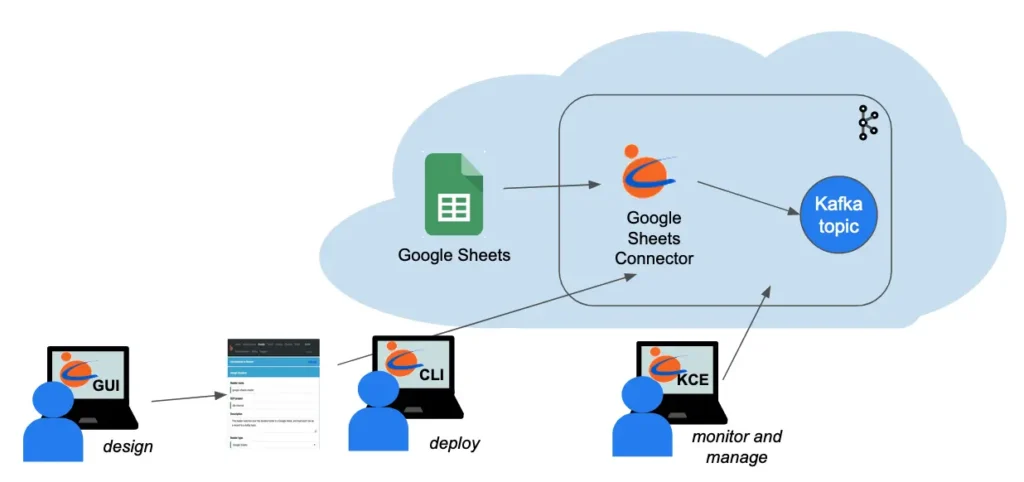
You, the user, design the reader using Calabash GUI. Then you can issue one Calabash CLI command to deploy it to the cloud. In the entire process, you never write code, but the deployment process will automatically generate code, configuration, and security setup for you. While the reader is running, you can use Calabash KCE to monitor and manage it.
Kafka has created an open platform for users to write and deploy connectors suitable for the users’ own situations. This is both good and bad. It is good that users will have the freedom to deal with their specific problems. But it requires advanced skills to write the connectors. Some development teams decided to stay away from Kafka-Connect due to its complexity. Unfortunately, they have missed a great technology, and they cannot avoid recreating wheels.
Calabash has created a set of ready-to-use Kafka connectors that cover a great spectrum in the business world. Users can design their readers by selecting from the Calabash readers.
If what you need is not on the list, Data Canals also offers professional services. We will develop readers to your specification and provide follow-up maintenance service contracts. If you are interested in getting help from Data Canals, please send us an inquiry at the Professional Service Inquiry page.
8. Further Reading
Calabash can also help you create writers similarly as readers. Writers save data from Kafka to persistent media. For an example of that use case, please check the article Saving Data from Kafka without Writing Code.
Users may use Kafka topics as the data gathering points for heterogeneous applications. To that end, you would only need readers and writers. However, that functionality is perhaps less than half of what Kafka can do.
You may also process the data in Kafka by creating data pipelines in Kafka Streams. Calabash can also help users create and manage data pipelines without writing code. For an introduction with a concrete example, please read A Simple GUI for Kafka Streams.
For a summary of all use cases of Calabash, please refer to the article Summary of Use Cases.
For product information about Calabash, please visit the Data Canals homepage.
The Calabash documentation site contains all the official articles from Calabash. The documentation includes extensive tutorials that lead readers in a step-by-step learning process.
For theoretical-minded readers, we recommend the introductory article What is Data Lake. You will understand that Calabash has a much more ambitious goal than helping users use Kafka.
A data lake is vital to any business if it wants to “examine” itself. Socrates must be pleased to see the proliferation of data lakes.