This article is a deep dive into Calabash with background and usage models.
Calabash has a web-based GUI and a command-line interface (CLI) tool. The GUI is for designing data lakes, i.e., the systems for collecting and processing real-time data. The CLI is for deploying the components of these systems to the cloud, i.e., the “runtime.”
1. The Calabash GUI Designer
Using Calabash GUI, you create objects only in the Calabash repository. They are not in the cloud yet. So you incur no cost on the cloud platform. Furthermore, a browser is all you need to do the design work. You do not need to install anything.
The Calabash GUI is at https://calabash.datacanals.com. Register and log in to the Calabash repository to start your design work.
The user manual for Calabash GUI is in the Calabash GUI article category. The first article to read in this set is Overview of GUI and Data Systems.
2. The Calabash Runtime CLI
The runtime CLI tool is an interactive application that must run on a local host having the privilege to access your cloud platform. Typically it is your laptop.
You will also need to log in to the Calabash repository in the CLI to access your designs.
The user manual for Calabash CLI is in the Calabash CLI article category. The first article to read in this set is Overview of CLI.
3. Components in a Data Lake
The data system for collecting and cleansing source data is generally referred to as a “data lake.” You need a firm grasp of what you can find in a data lake, but it only needs to be on a very high level. You do not have to be an expert in the technologies involved. Taking care of those monstrous details is the job for Calabash.
The diagram below shows all the components in a data lake.
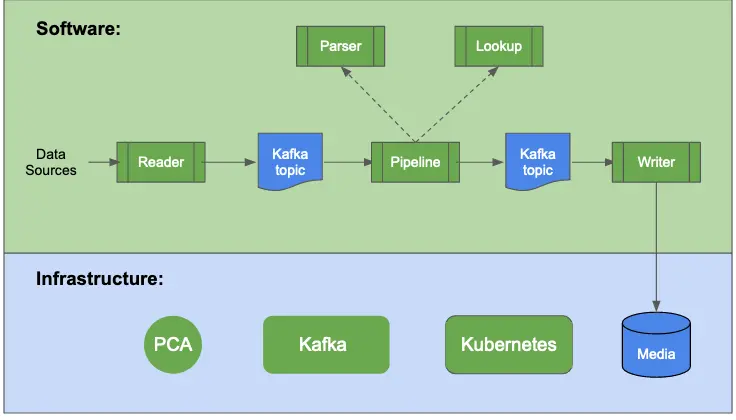
All the dark green boxes in the above illustration represent objects you can design using Calabash GUI. After the design, you can deploy them to the cloud using Calabash CLI. The blue boxes represent data in your data lake.
3.1. Infrastructure
The first step in the data lake design is to build your cloud infrastructure. This infrastructure includes all the static cloud resources you will need.
Specifically, you will need to create one Private Certificate Authority (PCA), one Kafka system, and one Kubernetes cluster. They are used for the following purposes.
- PCA. The PCA is needed to facilitate TLS (SSL) communication among all components in the system.
- Kafka. The Kafka system is the real-time storage and processing engine. It holds data in “Kafka topics” for seven days by default. You may see the need to create writers to offload data to permanent media.
- Kubernetes. The Kubernetes system coordinates distributed processes working on the same data load. It provides dynamic scaling, fault tolerance, and load balancing. Kafka runs a majority of processing on Kubernetes.
Not shown in the above illustration is a VPC network. Although the cloud platform automatically provides a default network, for best practice, it is recommended you create a custom VPC network plus custom subnets within it. You may use either Calabash or the cloud platform console for creating this VPC network and subnets.
Please read details about VPC Network in Google Cloud Platform.
3.2. Software
Infrastructure only provides the material foundation. It is the software that accomplishes your goals. However, you are not going to develop software.
For all the software objects shown in the above illustration, you only specify their properties using Calabash GUI. Calabash will generate implementations for you when you deploy those objects to the cloud. Then Calabash will place them in sound environments and launch them in the correct order. In short, you hold the steering wheel, and Calabash coordinates the components to move in the desired direction.
Here is a brief explanation about the software components, i.e., those dark green boxes in the “Software” section in the above illustration.
- Reader. A reader reads from a data source and monitors its changes. As soon as the reader sees new data, it sends them to a Kafka topic. The reader is data-driven and runs 24×7. You will never need a scheduler (such as Apache Airflow) to manage it.
- Writer. A writer does the opposite of a reader. It reads data in a Kafka topic and dumps them to a persistent media, such as a cloud storage file, a JDBC table, or a Google Bigquery table. It can also post data to a webhook. Writers also work in real-time 24×7.
- Pipeline. A pipeline can convert one data stream (in a source topic) to another stream (in a target topic). It does this conversion by putting every record through a series of “processors.” A processor may perform dedup, filter, parsing, lookup, group transformation, and record transformation. The combinations of these processors can accomplish any data processing logic, commonly called “ETL transformations.” Using Calabash GUI, you can create highly sophisticated pipelines quite easily.
- Parser. A parser is a function that deserializes a string to a structured object. Parsers are the ways for a pipeline to inspect the data. When loaded from a source for the first time, the data are of poor quality, containing human errors, mixed-structure objects, or no structure at all. Parsers help identify what is in this “murky water.” The parsing result, either success or failure, can give you more information about the raw data. After running several parsers, you can usually separate the input stream into several cleaner streams, each with a well-defined structure.
- Lookup. A lookup is a function that uses a key to search a lookup table. The lookup table could be in a file, a database, or Google Sheets. Lookups in Calabash can also call REST APIs. You use lookups to enrich data records if they do not have the information you need.
4. An Example
To give you some idea about building a data lake using Calabash, let’s take a cursory look at an example.
You can see what the Calabash GUI looks like from the following screenshot. It has menu items across the top of the page for all the major components such as infrastructure, reader, writer, pipeline, etc.
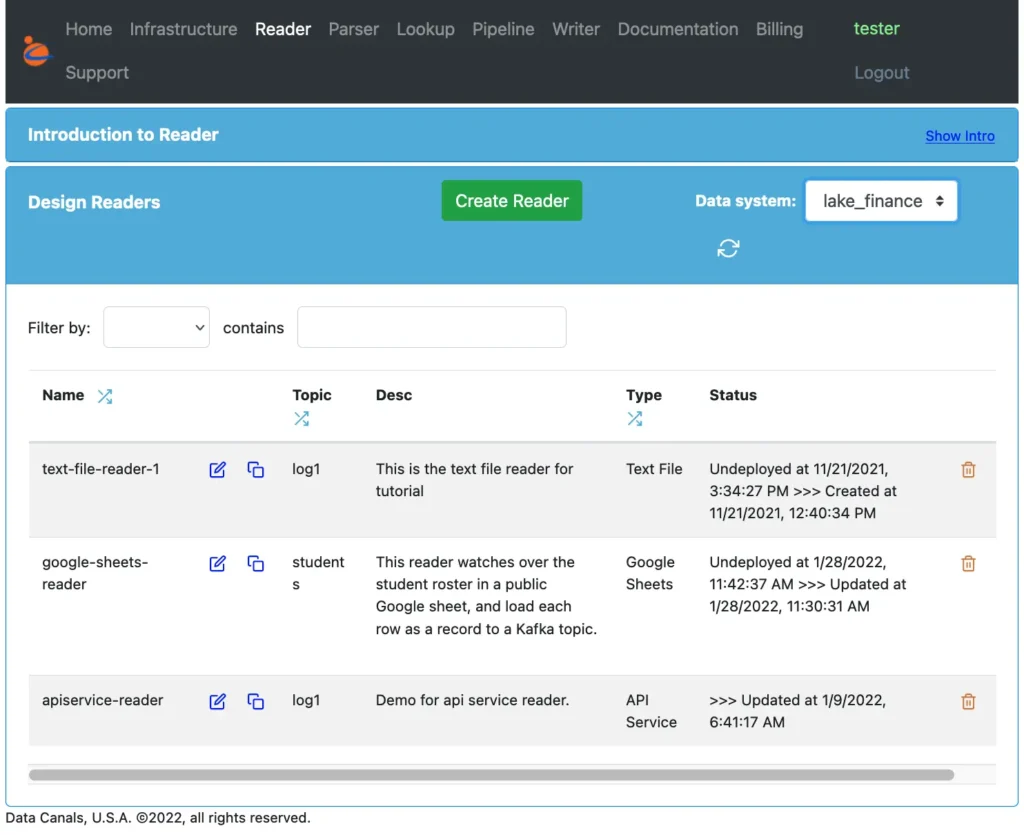
The above screenshot shows that we have selected the reader page as the current page. This page contains a list of all readers we have created in a data system. In the above screenshot, the data system is “lake_finance.”
There is a refresh button under the “Data system” label. You can click on this button to get the most up-to-date list of readers.
To edit reader properties, click on the edit button by the reader name. The editable list of properties will show. For example, the properties for the first reader (the “text-file-reader-1”) include the URL of the file and the target topic. We will skip the screenshot for the details.
Creating a pipeline follows the same usage model. You first click on the “Pipeline” menu item in the top menu to make the pipeline page your current page. Then you create a pipeline object and edit its properties.
The following screenshot shows sections in the property editor for a pipeline. You can see properties can be simple, such as “Source Kafka topic.” They can also be complex, e.g., the “pipeline processors” property.
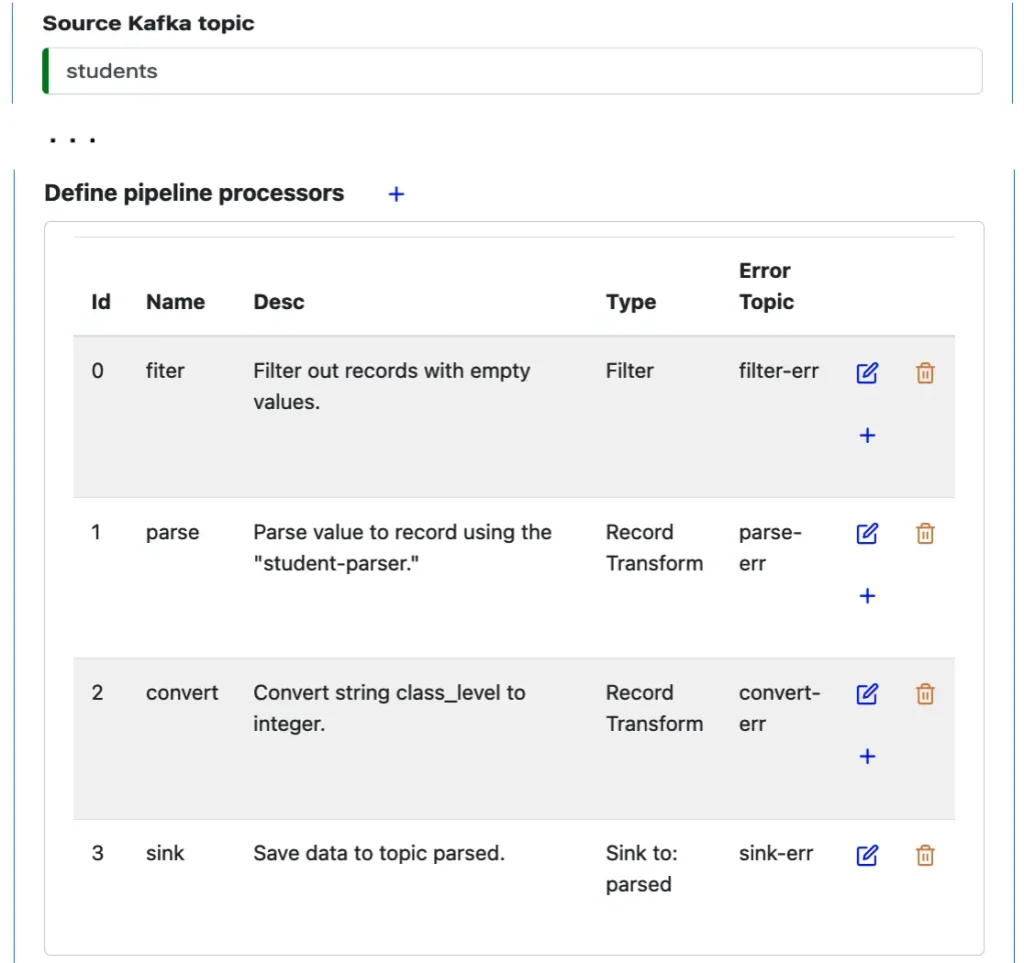
The “pipeline processor” is a list of processors. The first processor is a “Filter” processor, which checks if every record in the flow satisfies a Boolean condition. The second processor is a “Record Transform” processor, which converts each input record to one output. And finally, the Sink processor saves the result to the target Kafka topic with the name “parsed.”
The data pipeline must run on some hardware. Specifically, it needs a PCA, a Kafka, and a Kubernetes cluster. To create these, use the “Infrastructure” page. The GUI usage model stays consistent with what we have seen above.
After the design, it is the time when the rubber hits the road. In the following transcript, you can see Calabash CLI in action.
% bin/calabash.sh Calabash CLI, version 3.0.0 Data Canals, 2022. All rights reserved. Calabash > connect tester Password: Connected. Calabash (tester)> use ds lake_finance Current ds set to lake_finance Calabash (tester:lake_finance)>
We first run a script to start the CLI interactive shell. You can see the “Calabash >” prompt. We first connect to a user repository then set a data system context with the “use ds” command. The prompt reminds you of the connected user and the data system context.
We can list all the readers in this data system using the “list r” command.
Calabash (tester:lake_finance)> list r
Reader Name Project Description Type Status
--------------- --------------- ------------------------------ ------------------------------ ------------------------------
text-file-reade dlb-internal This is the text file reader f Text File Undeployed at 11/21/2021, 3:34
r-1 or tutorial :27 PM >>> Created at 11/21/20
21, 12:40:34 PM
google-sheets-r dlb-internal This reader watches over the s Google Sheets Undeployed at 1/28/2022, 11:42
eader tudent roster in a public Goog :37 AM >>> Updated at 1/28/202
le sheet, and load each row as 2, 11:30:31 AM
a record to a Kafka topic.
apiservice-read dlb-internal Demo for api service reader. API Service >>> Updated at 1/9/2022, 6:41
er
To deploy a reader, we use the “deploy r” command. If the deployment is successful, you will see a confirmation message.
Calabash (tester:lake_finance)> deploy r google-sheets-reader Deploy to cloud? [y]: Deployed to Kafka-Connect @ https://34.132.10.172:8083 Calabash (tester:lake_finance)>
Type “list r” again. You can now see the status shows information about the successful deployment. At this time, the reader is alive!
There is also an “undeploy r” command, which removes the reader from the cloud. It also cleans up cloud resources occupied by the reader.
Calabash CLI is self-documenting. Just type “help” whenever you need it. It will list all commands valid in your current context, for example:
Calabash (tester:lake_finance)> help list i - list all infrastructure objects in the data system list r - list all readers in the data system list p - list all pipelines in the data system list w - list all writers in the data system desc i - see details of an infrastructure object desc r - see details of a reader desc p - see details of a pipeline desc w - see details of a writer deploy i - deploy an infrastructure object deploy r - deploy a reader deploy p - deploy a pipeline deploy w - deploy a writer undeploy i - undeploy an infrastructure object undeploy r - undeploy a reader undeploy p - undeploy a pipeline undeploy w - undeploy a writer set-up-ssl - create SSL key and certificate supported by a PCA set-up-kce - set up a Kafka client environment on this host to interact with the Kafka system at pca - get the access token of a PCA at r - get the access token of a reader reset-at - reset access token of a reader code-gen - generate pipeline code export-ds - export metadata according to the spec file import-ds - import from the metadata file list ds - list all data systems you can access desc ds - see details of the data system use ds - use a data system connect - connect to Calabash server to access metadata help - show this message quit/exit/ctrl-C/ctrl-D - exit Calabash (tester:lake_finance)>