Kafka is difficult. You can find many articles discussing this subject. But it is not Kafka’s fault because the problem it solves is highly complicated. In the software industry, complexity calls for a better user interface.
The original idea of Calabash was to create a GUI for Kafka Streams, the most challenging part of Kafka. We hit upon this idea because we had decades of experience writing ETL tools. We saw the complexity from Kafka Streams fits exactly a pattern all ETL tools try to overcome.
On the one hand, we have “business people” who are experts in their real-world domains, but they have little programming skills. On the other hand, we have a team of developers armed to the teeth with shiny tools (such as Kafka Streams), but they do not have a good grasp of the business. The communication between the two camps often breaks down.
The solution from Calabash is a development tool for business-minded people to define their data processing logic. The “business-minded people” refers to all who know the details of data in their organizations. Examples are architects, product managers, data scientists, data engineers, etc.
Specifically, Calabash offers a web-based GUI for users to describe, on a high level, filters, mappings, expressions, and conversions. Calabash generates implementation for the users, including code, configurations, SSL certificates, property files, etc.
Calabash goes to extreme helping users program Kafka Streams. Users do not even need to know what Kafka Streams is. But they can create highly complicated real-time processes (called “pipelines”) in Kafka Streams.
Calabash has overshot its original goal. It is now a lot more than a GUI for Kafka Streams. It helps users create and maintain their entire cloud infrastructures.
For example, users can use Calabash to describe the Kafka systems they need. Calabash then sets them up, taking the whole nine yards. Users stay on a high level throughout. (For example, they specify the number of zookeepers, brokers, the machine types, etc.) They do not need deep knowledge and skills in Kafka.
Sounds like Calabash is just a user interface for Kafka. Actually, no. It is more than that, too. For example, if users need to create microservices or websites, Calabash can help set them up in minutes.
In general, we consider Calabash a “Data Lake” builder. A data lake is a highly complicated real-time data system for “purifying” the worst kinds of data in a business. Therefore, a data lake must harness a large spectrum of software technologies.
However, the focus of this article is on the user interface for Kafka Streams. Readers interested in data lakes and how Calabash helps build them are referred to the Calabash documentation for more details.
In this article, we will first go over an example pipeline. You will see how the GUI looks like. And you will get a general idea about how to do pipeline design using Calabash. We will also deploy the pipeline and watch it running.
Towards the end of this article, we will serve some theoretical “dessert” for interested readers. Building real-time data pipelines is not only a matter of technicality. It is also a strategic decision for you business going forward. It embodies a break away from the traditional methodology for “data quality.”
1. The Example
A pipeline always starts from a source topic. In our demo, the source topic (named “students”) contains data looking like these:
"1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:4"|"Anna,Female,1. Freshman,NC,English,Basketball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:6"|"Benjamin,Male,4. Senior,WI,English,Basketball" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:8"|"Carrie,Female,3. Junior,NE,English,Track & Field" "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:9"|"Dorothy,Female,4. Senior,MD,Math,Lacrosse" ...
Each line is a record with a key and a value. (Kafka records are key-value pairs.) We use vertical bars to separate keys and values above. For the sake of simplicity, keys and values are all strings.
Requirement #1: Drop records with empty values.
The keys in Kafka can never be empty, but the values may. So the first step in the processing logic is to eliminate records with null values.
Requirement #2: Convert “class level” to numeric.
For example, convert “1. Freshman” to 1 and “4. Senior” to 4. Perhaps in a follow-up pipeline, we will aggregate on the class levels. Therefore, we do some preparation by normalizing the class level here.
Requirement #3: Save the result to a topic named “parsed.”
The pipeline sounds very simple. But it has a hidden requirement: we must parse the values to access the “class level” field. Parsing is the functionality that can make any data system intelligent. Calabash allows users to design parsers.
2. Design the Pipeline
Using the Calabash online GUI, you will first design a blueprint (or metadata) for a pipeline. Then you will download the Calabash CLI and use it to deploy the blueprint to the cloud. The design will stay on a high level. And to start the deployment, you will need to type just one Calabash CLI command.
The deployment process will generate code, configurations, and property files according to your blueprint. When all is fine, it will start the pipeline.
To design the pipeline, start a browser, and go to the Calabash GUI at https://calabash.datacanals.com. Log in, and start the create pipeline form. See below.
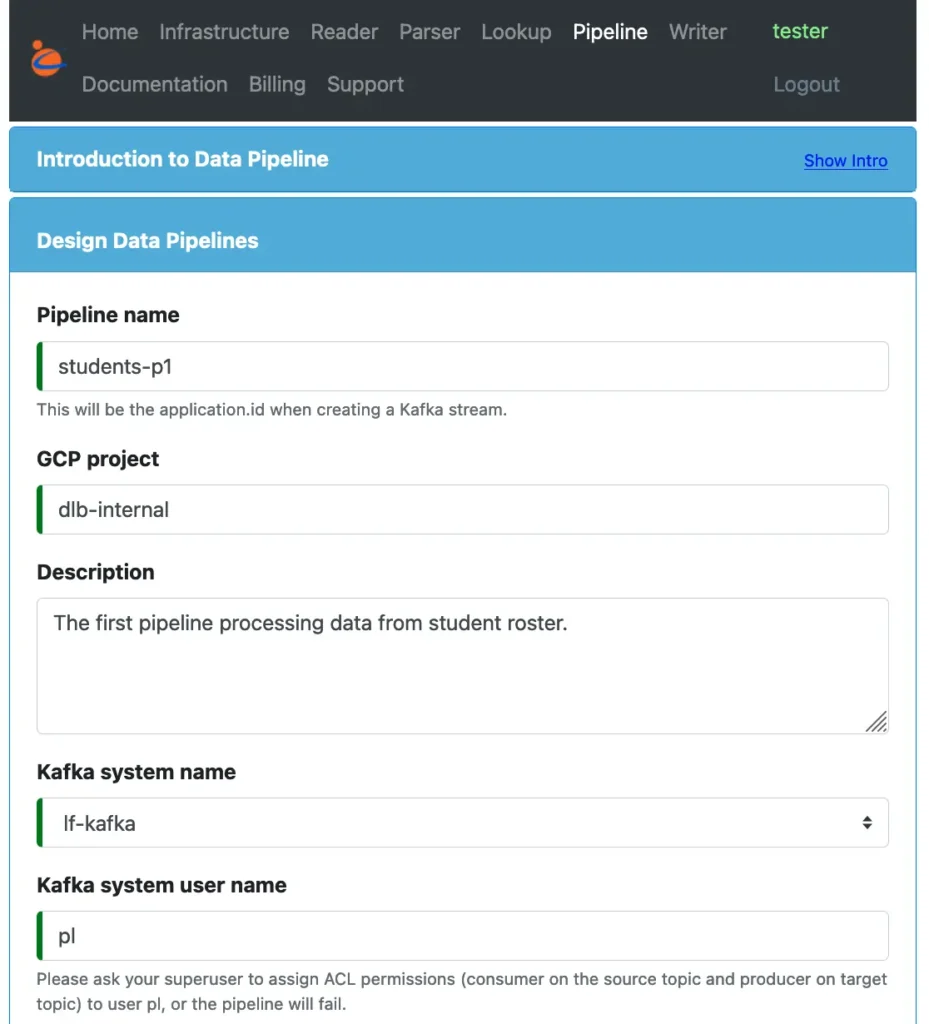
Enter some names, including the pipeline name, the project name, the Kafka system name, and the user name for the pipeline.
The pipeline is assigned with a user name in the Kafka system for controlling its access permissions. The Kafka superuser can manage this user to ensure it only accesses its intended resources. In our example, we use the name “pl.” You may choose any name for the pipeline user name. The deployment process will create credentials for “pl.”
Next, you need to describe the source topic. Every pipeline starts with loading data from a Kafka topic.
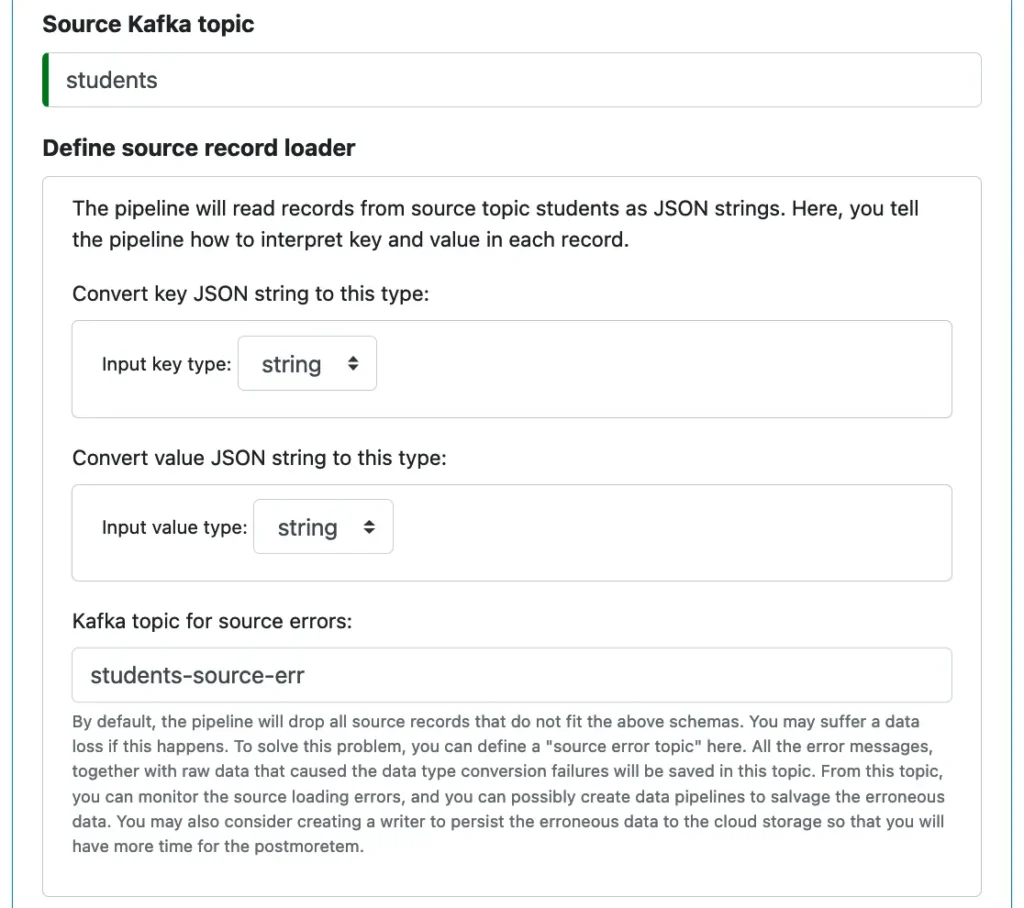
In our example, both the key and the value in a record are strings.
As the above screenshot suggests, there may be other options in the drop-down lists for types. One other option is “record,” for describing arbitrary source objects. Being able to process any data is a big topic in its own right. We will skip that discussion in this article.
Pay attention to the “Kafka topic for source errors.” This is the topic for erroneous source records. An exception will be raised if the pipeline cannot convert the string data to the record types. But since both keys and values are strings in this example, there will be no data type conversions at runtime, hence no errors. We could have left this error topic empty.
In general, Calabash allows you to create an “error topic” at every point where errors may happen. The error-tracking-and-redirecting feature will be in the generated code. It will make debugging the pipeline infinitely easier. Please also read the hint in the above screenshot.
Next, we define a sequence of processing stages called “processors.”
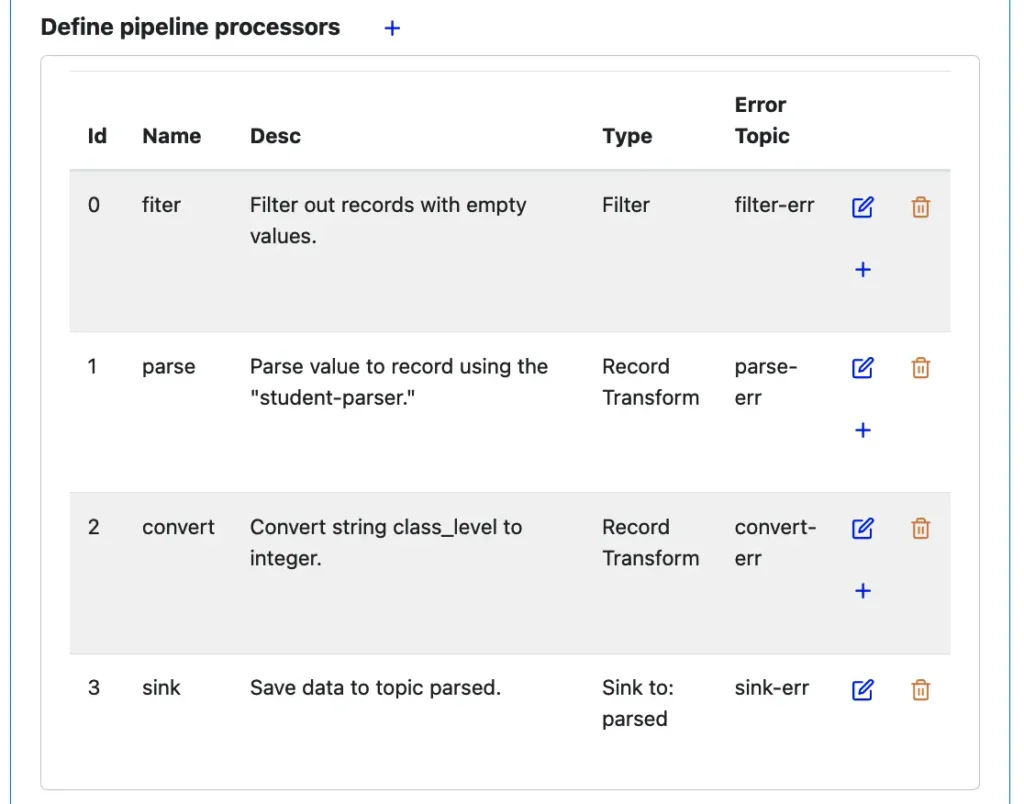
The above screenshot shows four processors have already been created. In the following three sections, we will see how they are designed. Below we will go over some general concepts about the processors.
Kafka data records flow through these processors one after another. The output of one processor is the input of its successor. Calabash allows you to design five types of processors:
- Filter: drop any record that does not satisfy a Boolean condition.
- Deduplication: randomly keep only one record among records with the same key.
- Record transformation: produce one output record for each input record.
- Group transformation: calculate one output record from multiple input records of the same key.
- Sink: send data to a topic.
These processors are sufficient to implement any business logic.
We can imagine from the above design that a record first goes through the filter processor. If it can survive the filter condition, it flows to the record transform processor named “parse.” In this processor, the string value in the record is converted into an object using a parser named “student-parser.” (We will briefly describe how to design a parser later.)
The parsed record goes through another record transformation to convert the “class_level” field from string to integer. Now you can see why we have to parse the value: for accessing the “class_level” field.
Finally, the processed data are sent to the target topic named “parsed.”
We could have combined the two record transformation processors (“parse” and “convert”) into one. But if we did that, we could have a hard time understanding error messages. Separating them into two record transformations provides clean tracking of causes.
Furthermore, the number one design principle for pipelines is to keep each stage simple. The worst thing in the runtime is the so-called “pipeline stall.” It is a disastrous situation where upstream stages see records blocked by one long-running downstream processor.
Keep in mind that all processors run in parallel. Separating the “parse” and the “convert,” we actually increased the degree of parallelism. Consequently, the throughput improves.
In the following three sections, we will describe the design for a filter, record transformations, and sink processor. To bring up the design form for a processor, you can click on one of the blue plus signs in the above screenshot. Or, you can click on an edit button to modify an existing design of a processor.
3. Design the Filter
The following screenshot is for creating the filter processor.
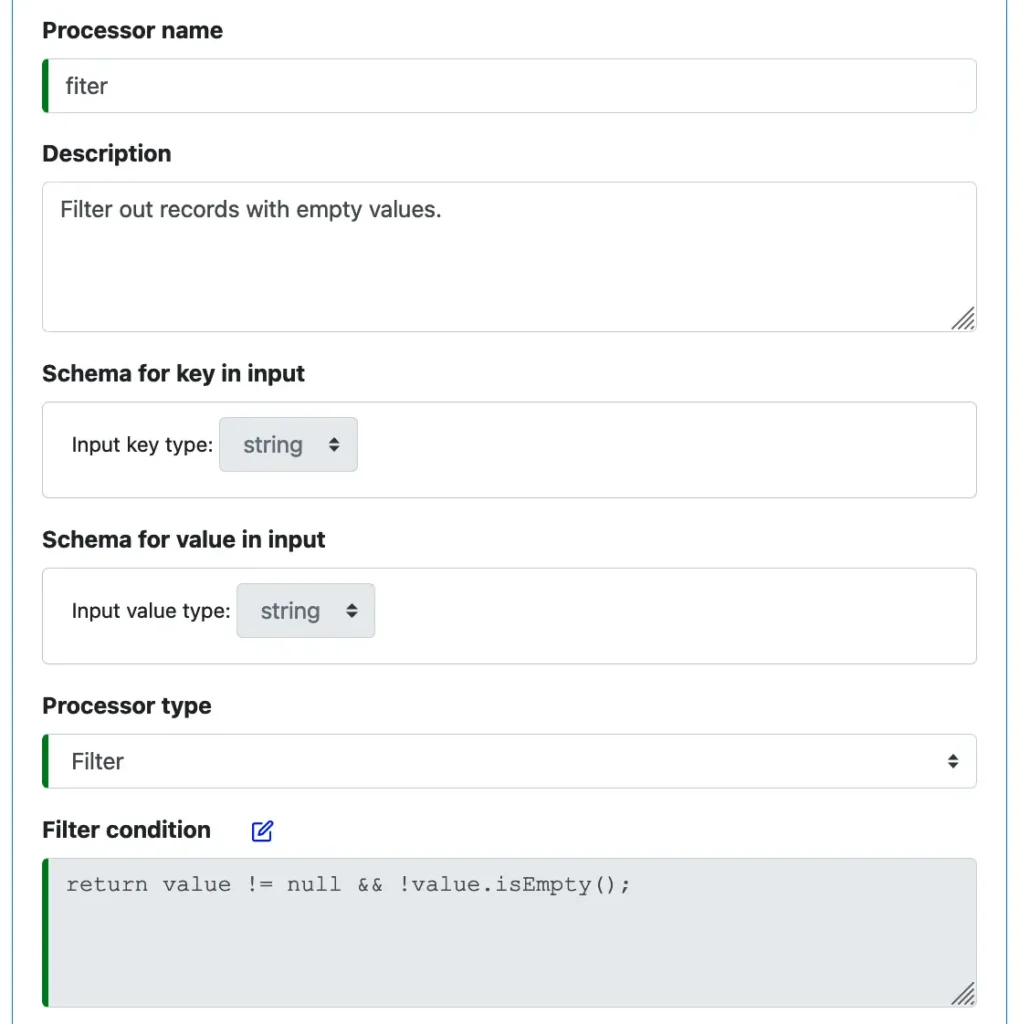
All straightforward, but there is a point to ponder over. The filter conditions must be written by users as valid Java expressions.
Calabash relies on the standard Java as the medium when connecting to users’ business world. This method gives users complete freedom to create any rules they like using the expressive power of the Java language. If the users have basic knowledge of Java, they instantly know what to do in Calabash.
Almost all ETL tools in history created the so-called “expression builder” for users to enter their business rules. But experience proved, again and again, it is a bad idea.
First, the expression builder creates an unfamiliar environment for users. So it requires additional learning. We observed that users always wanted to see the generated code (which is more familiar and less ambiguous to them) after creating the expressions using the GUI. Second, the more “help” an expression builder offers, the more restrictive it becomes. If users wanted to add complicated calculations, they often needed to use the advanced “custom” option. It made the already complex problems messier.
But the drawback of letting users write Java code is the concern of correctness. What if the code does not compile?
Calabash offers the “code-gen” command in Calabash CLI. Users can compile the pipeline before deploying it. The base code (i.e., the code free of user expressions) is known to be error-free. So if the compilation fails, all errors would be from users’ code. They can peruse the error messages, locate the bugs, and make changes. Using Calabash GUI and CLI, you have a development platform for data pipelines.
The code-gen command will be demonstrated later.
4. Design the Record Transformations
Choose a good name for the processor. It only needs to be unique among processors in this pipeline. Then add some descriptions. See below.
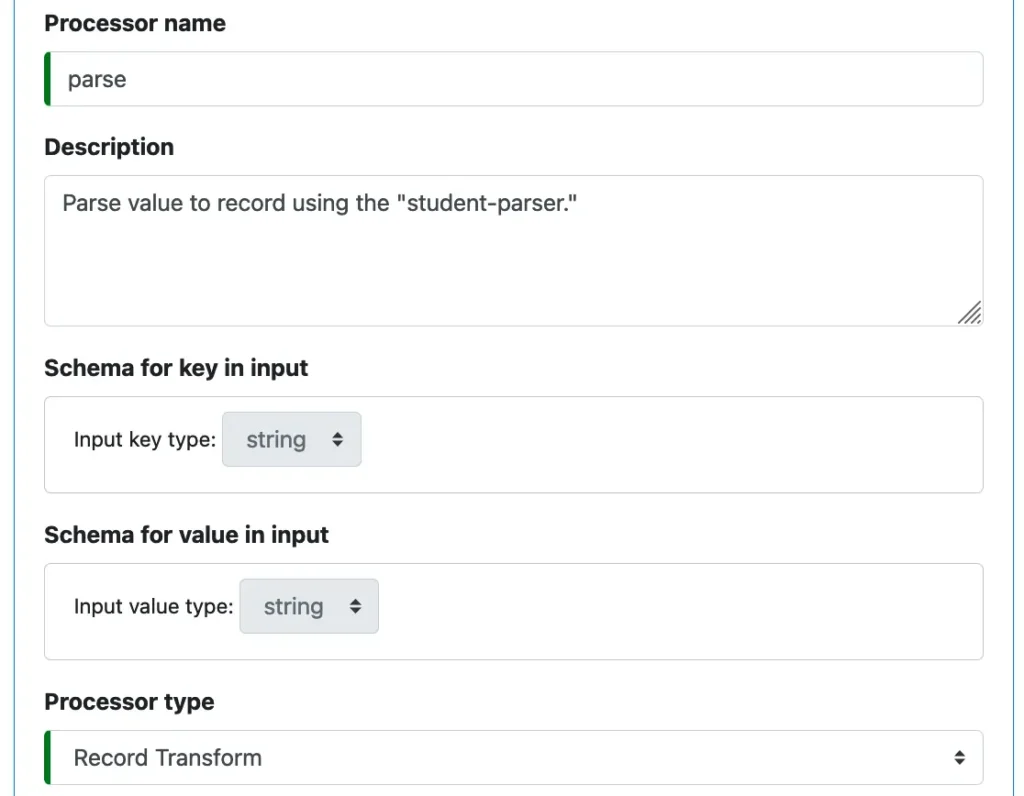
The input data types (or “schemas”) are automatically filled in by Calabash since it knows the input types for this processor already.
We have selected “Record Transform” from the list of processor types in the above screenshot.
A record transform calculates one output record from an input record. The types of the output record are up to the users to design. They can be anything.
The following screenshot shows the output schemas we have created.
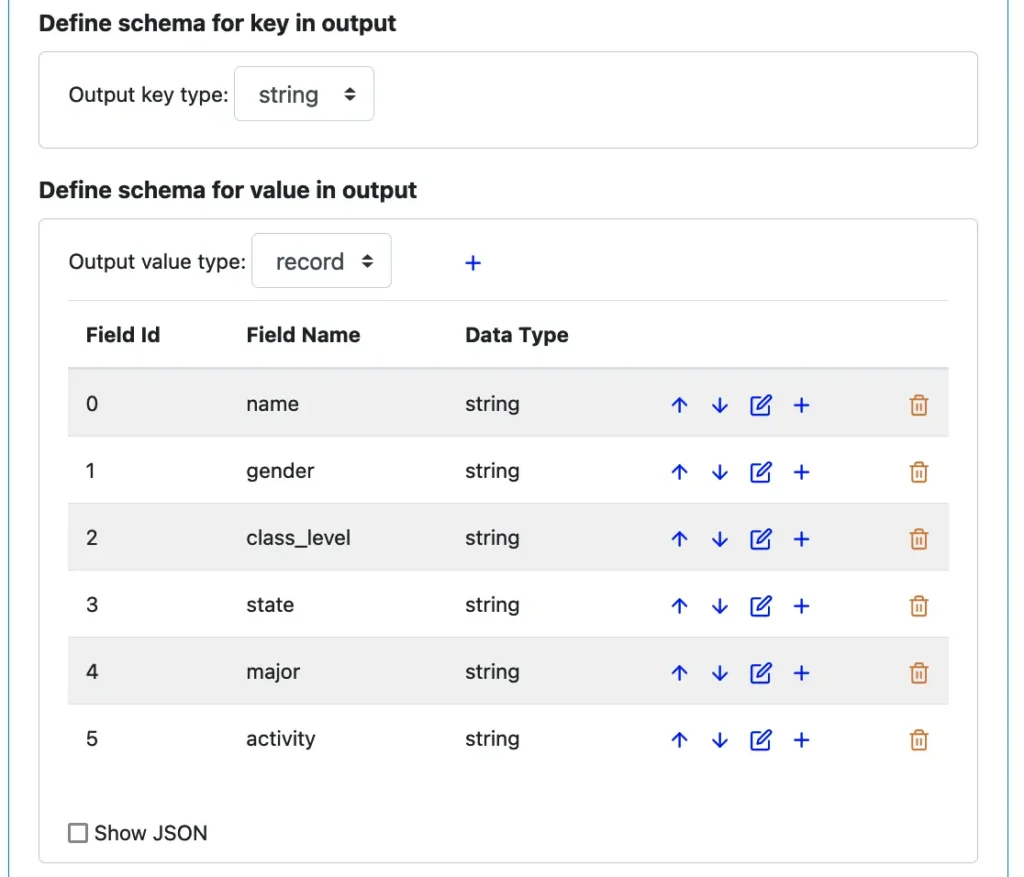
The key will stay as a string. We intend to preserve the key from input to output.
But the value will be a record with many string fields. You can use the blue plus buttons in the above screenshot to add fields. You can also edit fields for names and data types. You can delete them or move them up/down in the list.
Next, we define the processing logic for producing output records from the input.
Calabash allows us to first run some preprocessing logic before creating output fields. The result calculated by the preprocessing will be stored in a global variable (named “pre”). This way, we can avoid repetitive calculation of the same intermediate values when producing output fields.
In our example, we want to call the parser, which will convert the string value to a record. It is done with the following code:

In the above, “Parser” is a Java class provided by Calabash in the generated code. And “parse()” is a static method in this class. It takes a string value and converts it to a record. You may have several parsers, so name the one you want to use in the “parse()” call.
We must design the parser using Calabash before creating the pipeline. We will see all the details about creating parsers shortly.
In this example, our parser is named “student-parser.” The parse() call returns a record with the following Java type:
Map<String, Object>
A preprocessing result is returned by the about preprocessing code. And, as we know, it will be stored in a global variable named “pre.” We will later use “pre” to produce values for the output. This way, we avoid repeated parsing of the input string for every output field.
Next, we start to calculate output fields. The key is simple: just return the input key as the output.
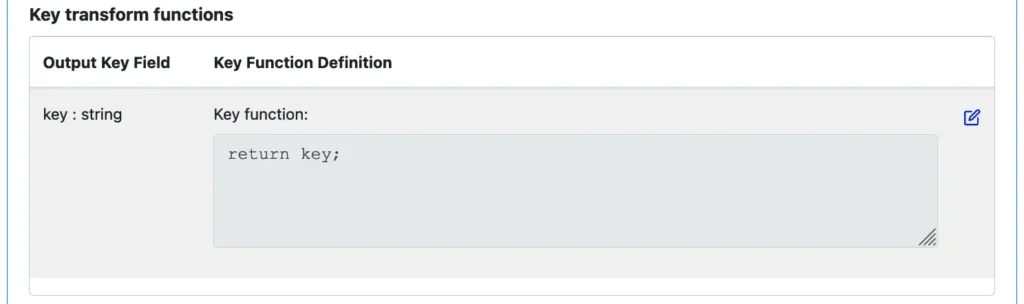
The value in the output will be a record. The parsed input is in the global variable “pre.” We will just need to retrieve the parsed fields from this intermediate variable.
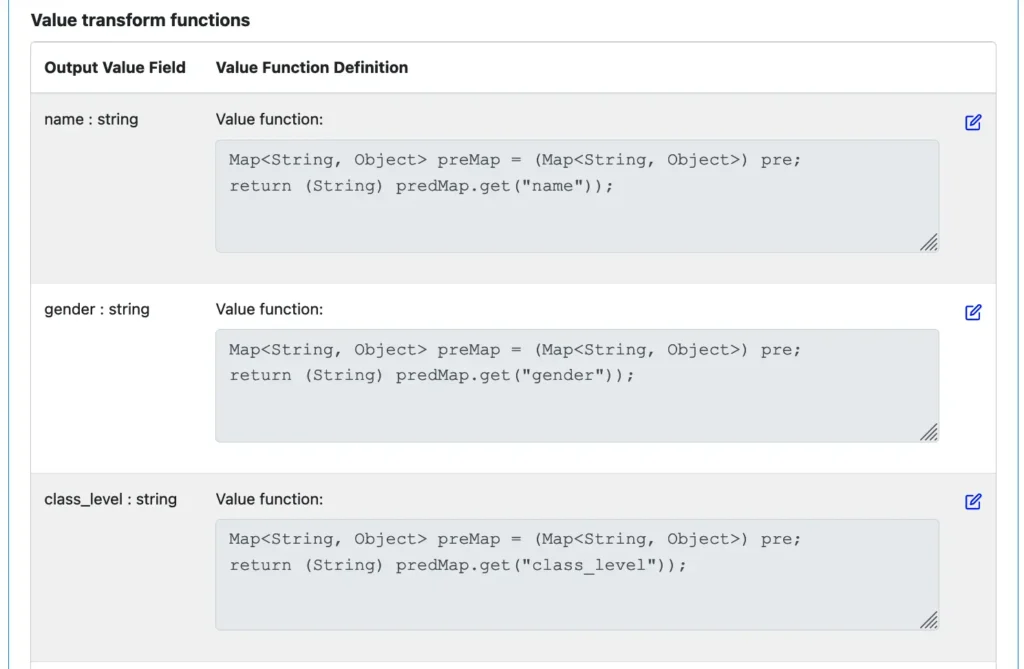
And there we have it, the transformation from string to parsed record! To conclude this section, let’s take a look at parsers.
Calabash offers a designer for parsers. A parser analyzes a string and turns it into a record. You can use Calabash to design the following types of parsers:
- CSV: for a CSV string
- JSON: for a serialized JSON string
- Text: for an arbitrary text line.
If the string is a text line, you will be asked to define how to identify each field from this line. But for CSV or JSON, you do not need to do so.
In the following screenshot, you can find the design for the “student-parser” (a CSV parser).
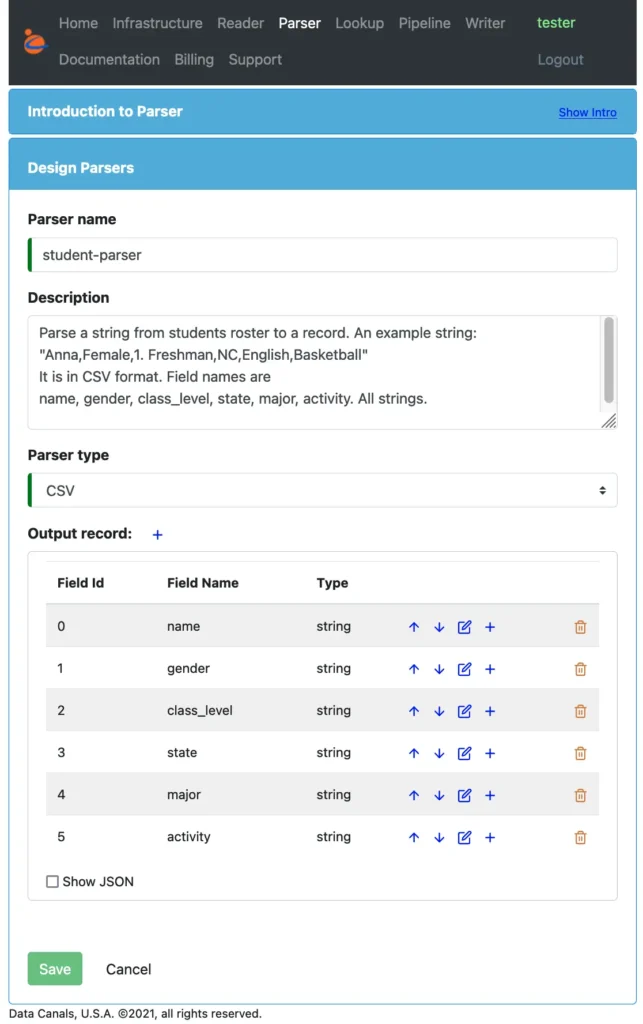
The users need to define what the output fields look like. The output will always be in record form. The schema can contain arbitrary subtype embedding. You can do deep deserialization if it makes sense. For example, deep deserialization makes sense for JSON parsers, but it does not make sense for Text and CSV parsers.
The parser can be used in a record transform processor (as demonstrated in this section) to turn a string into a record. Then downstream processors will be able to access fields.
We will skip the details of the downstream processor, named “convert,” in our example because it is straightforward. This processor converts the “class_level” field from string to integer.
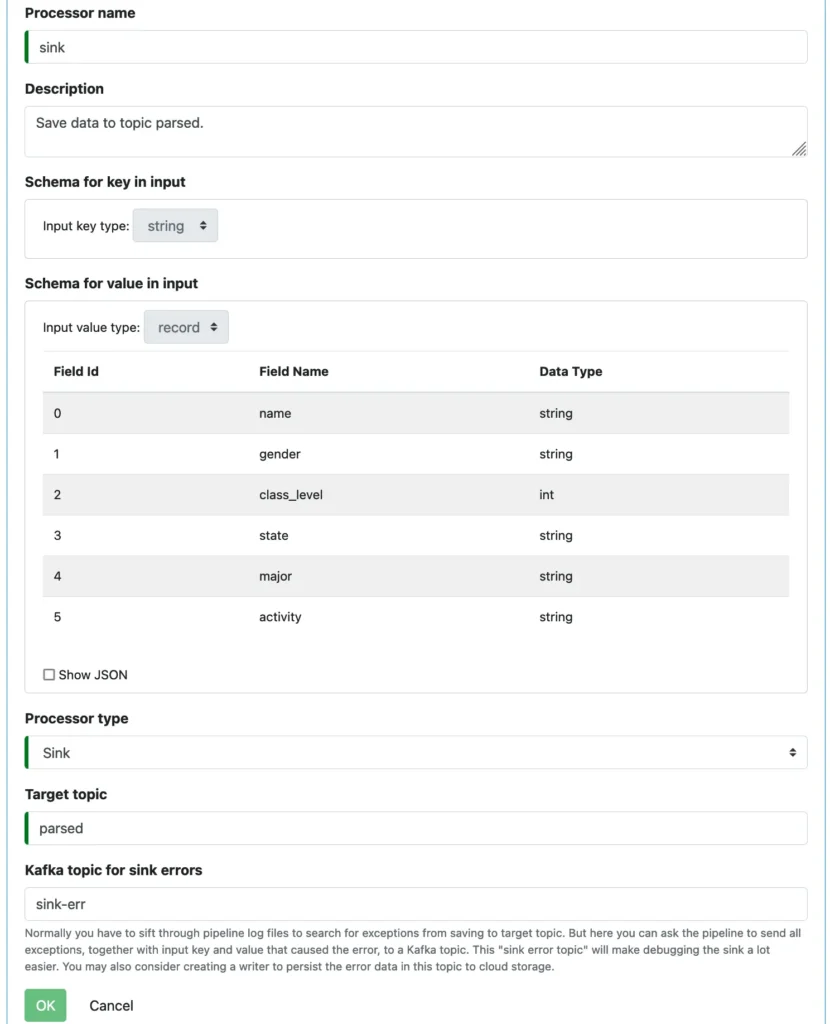
5. Design the Sink
The sink is simple. You only need to fill in the name and target topic. Optionally, but highly recommended, you can add an error topic. The record schemas are automatically copied here from the output of the predecessor processor.
6. Generate Code
Before deploying the pipeline to the cloud, we must check its correctness by compiling it.
To compile the pipeline, issue the “code-gen” command in Calabash CLI. Here is how we do this for the “students-p1” pipeline.
Calabash CLI, version 3.0.0
Data Canals, 2022. All rights reserved.
*** Test mode: container ***
Calabash > connect tester
Password:
Connected.
Calabash (tester)> use ds lake_finance
Current ds set to lake_finance
Calabash (tester:lake_finance)> code-gen students-p1
Enter a directory for the generated code: /tmp/codegen
mkdirs /tmp/codegen
mkdirs /tmp/codegen/generated/build/libs
java.lang.Exception: Compile failed: Failed with compile errors:
Error #1: /com/dcs/kafka/pipeline/generated/CustomFunc.java:135: error: ';' expected
return value != null && !value.isEmpty());
^
...
You will be asked for a temporary directory for the generated code. Then Calabash will produce the code and compile it. If there are any problems, the detailed error messages will be displayed on your screen.
You can easily see where the problem is. For example, we intentionally introduced an extra closing parenthesis in the filter condition. The compiler shows the line and points you to the place of error. The line number in the error message refers to the generated file in the codegen directory.
You can go back to Calabash GUI, fix the error, and issue “code-gen” again.
7. Deploy the Pipeline
When the codegen does not have any errors, we can deploy the pipeline to the cloud. To deploy the “students-p1” pipeline, just type the “deploy p students-p1” command in Calabash CLI. Here “p” stands for “pipeline.”
That is all we need to do.
There are two infrastructure options to run a pipeline. You can deploy it to a stand-alone VM or to a Kubernetes cluster.
8. Monitor the Pipeline
8.1. Check the Log
There are several ways to watch the health of the pipeline. One is to check the log file. The log file is located in the “/data/log” directory within the Docker container running the pipeline.
For example, suppose we deployed a pipeline to a VM. It is run in a container on this VM. Connect to the shell of the container, then you can find out:
root@9ef826ac8a10:/data/logs# ls pipeline.log prepare_pipeline.log root@9ef826ac8a10:/data/logs#
Both log files should be checked. There should be no exceptions.
8.2. Check the Data and Error Topics
You should test your pipeline by comparing source and target records before production.
Study if the pipeline has performed the expected processing. For example, the data in the source topic contain:
Record# Key Value
------- --------------------------------------------------------------- ------------------
0 "1638252732405-1A8_gvuZmZuu6m3dW8JGWcqnh0KQsJC_CXfPQEBPau7A:3" ""
1 "1638252732405-1A8_gvuZmZuu6m3dW8JGWcqnh0KQsJC_CXfPQEBPau7A:5" "05/04/2021 16:34:10,account0000002,100"
2 "1638252732405-1A8_gvuZmZuu6m3dW8JGWcqnh0KQsJC_CXfPQEBPau7A:10" "05/03/2021 12:30:30,account0000001,1000"
3 "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:4" "Anna,Female,1. Freshman,NC,English,Basketball"
4 "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:6" "Benjamin,Male,4. Senior,WI,English,Basketball"
5 "1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:8" "Carrie,Female,3. Junior,NE,English,Track & Field"
...
Record 0 has an empty value. The “filter” processor will filter it out. Records 1 and 2 do not match the student record type. The “parse” processor will take them as erroneous records. Records 3, 4, and 5 will appear in the final topic named “parsed.” The “class_level” field will be converted to an integer.
Checking the target topic, we find:
Key Value
--------------------------------------------------------------- ------------------
"1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:4" {"class_level":1,"gender":"Female","major":"English","activity":"Basketball","name":"Anna","state":"NC"}
"1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:6" {"class_level":4,"gender":"Male","major":"English","activity":"Basketball","name":"Benjamin","state":"WI"}
"1638266325784-1J71cyyyB6KW0l8-4SR5hOl6PztzbJkRNCWMl6Z1OPR4:8" {"class_level":3,"gender":"Female","major":"English","activity":"Track \u0026 Field","name":"Carrie","state":"NE"}
...
We see the expected result.
We can also check the error topic associated with the “parser” processor. And we find:
Key Value
--------------------------------------------------------------- ------------------
"1638252732405-1A8_gvuZmZuu6m3dW8JGWcqnh0KQsJC_CXfPQEBPau7A:5" {"val":"05/03/2021 02:05:23,account0000001,5000","err":"Failed processor preprocessing in step 1: Not enough fields in data: need 6 fields, but 3 found"}
"1638252732405-1A8_gvuZmZuu6m3dW8JGWcqnh0KQsJC_CXfPQEBPau7A:10" {"val":"05/03/2021 12:30:30,account0000001,1000","err":"Failed processor preprocessing in step 1: Not enough fields in data: need 6 fields, but 3 found"}
...
The error topic contains raw keys and values for erroneous records, plus the reasons for failing the parse.
8.3. Check Kafka Metadata
Calabash offers an environment for checking and updating Kafka metadata. This environment is called “Kafka Client Environment” or KCE.
A KCE is a directory you can deploy (using Calabash CLI) either to your PC or a container in the cloud. It contains all the credentials and property files for accessing your Kafka system. We will omit more details about the KCE because it is not the focus of this article.
In the “bin” directory in a KCE, you can find all shell scripts for managing the Kafka system. One of them is the “desc_consumer_group.sh” script. You can use it to check the progress of the pipeline.
root@bd9603609b09:/app/bin# ./desc_consumer_group.sh jdoe students-p1 GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID students-p1 students 0 32 32 0 - - - students-p1 students 1 39 39 0 - -
In the above example, “jdoe” is the superuser of the Kafka system. Most scripts in KCE can only be run be by a superuser.
The result gives us the pipeline progress in the two topic partitions. The LAG column is crucial. If a lag increases, the pipeline has stalled. In our example, we are in great shape.
9. Manage the Pipeline
A pipeline stall is an emergency situation. You must practice some emergency response actions.
The first action is to get the log files from the pipeline. Save it to your local machine for faster examination.
The second action is to stop the pipeline. This can be done with the undeploy command in Calabash CLI:
Calabash (tester:lake_finance)> undeploy p students-p1 Undeployed.
The pipeline code is idempotent. So it can be undeployed and redeployed at any time without any side effects. After diagnosis and fixing the problem, you can deploy the pipeline again.
The third action to consider is to suspend the reader. The pipeline is actually passive, but the reader is active. See the following illustration.
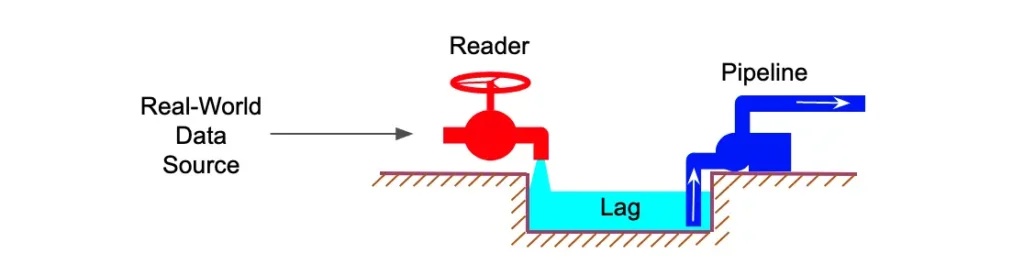
If there is no data, the pipeline will sit idle. But the reader constantly polls the data source. It pushes new data into the “pond” as soon as they appear. So the reader is active while the pipeline is passive. If you can suspend the reader, the pressure on the latter will be alleviated.
Calabash KCE offers a script (the “connector_pause.sh”) for suspending a reader. Pausing the reader can be done very quickly. It is like shutting the service faucet to a house.
But what would be the impact of shutting the reader? It depends on the nature of the source data. There will be no impact on the reader if the lifespans of the source data give you an ample amount of time to fix the pipeline issue.
If the lifespans of source data are extremely short (the so-called “hard real-time” data), you must use a different strategy. Instead of pushing data to a pipeline risking the pipeline stalls and potential data loss, you should immediately persist the data to the cloud storage.
Finally, the KCE also offers a script (the “connector_resume.sh”) for resuming a suspended reader.
10. Some Theoretical Throughts
We are now witnessing a widening gap between real-world data and the requirements of data analysts. Data analysts always need 100% correct data. But the explosion of real-world data makes it difficult, if not impossible, to eliminate junk data in time. Without a working data quality solution, the “big data system” may become a “bad data system.” It is a disaster if that happens.
Besides dirty data, it is also difficult, if not impossible, to forge data to the shapes immediately usable by data analysts. Their needs change on the minute scale, but data transformations usually take hours or days.
Consequently, data analysts must spend almost half of their time doing data preparation. It is a hugely wasted resource, accompanied by missed opportunities.
So here is the interesting question: can we build a data system that can always supply immediately usable data to the analysts? A Spark developer would say, “Sure, run my super fast Spark program. I will get your data ready in a few minutes.”
Spark can give us almost constant finishing time regardless of data volume. However, it is propped up by money. First, its initial resource investment is high. And second, as the data volume increases, you will need increasingly larger Spark clusters, hence higher cost. See the illustration below.
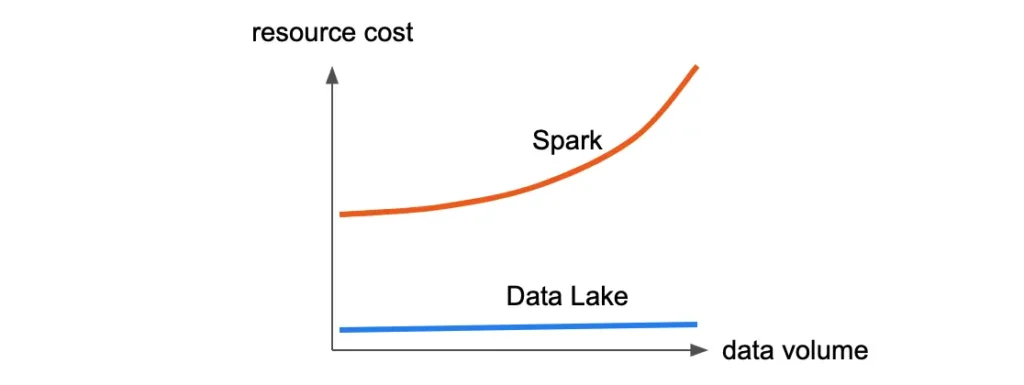
The above diagram illustrates the cost vs. data volume performance for Spark. The cost of Spark creeps up as volume increases.
In the same diagram, you can also see another performance line for “Data Lake.” That performance appears outrageous, but it is not a joke. A data lake can easily beat any batch processing method (such as Spark) in maintaining data quality. It will cost many times lower than Spark and can accept more load over time.
Time is on the data lake’s side! This is the reason for its outrageous performance, both literally and actually.
A data lake is real-time. It does data processing right away as soon as a record is admitted. One standard-size machine working non-stop every second for a day is equivalent to 24 of it working for an hour or 1440 machines working for a minute. How about we reserve 10 for a data lake? It is 14,400 machines working for a minute. A Spark cluster of that size will cost us dearly.
In essence, a data lake amortizes large computation jobs over time using only a small collection of resources.
But developing real-time processing is entirely different from batch processing. First, the system we use is already complicated, for example, the Kafka system. Second, it is not easy to acquire real-time development skills. Overall, there is a steep start-up resistance.
Calabash is created to remove this pain. With Calabash, users program their Kafka Streams pipelines (the best data lake processing engine so far) without knowing anything about Kafka Streams. Calabash is an enabler of real-time data quality processing. The outcome is the removal of the wasteful burden on data analysts.
11. Conclusion
A picture is worth a thousand words. The following diagram summarizes what we have demonstrated in this article.
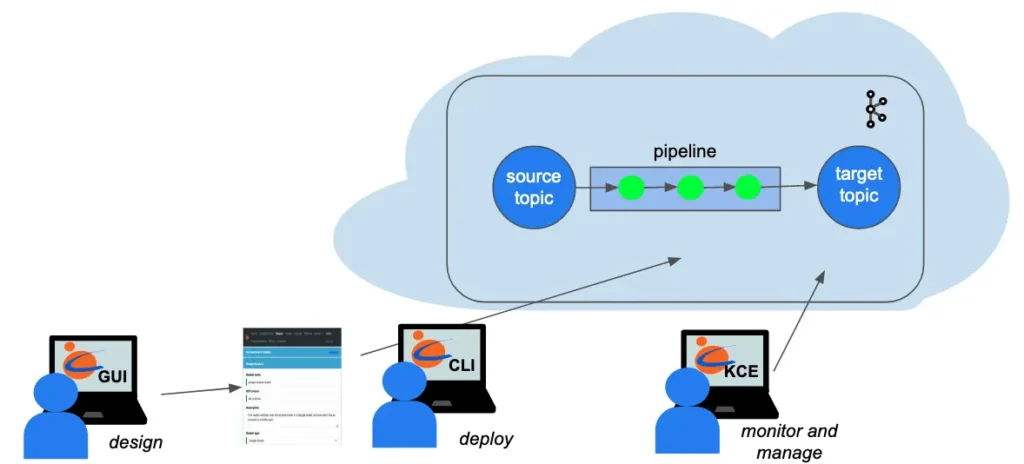
You, the user, design the pipeline using Calabash GUI. Then you can issue one Calabash CLI command to deploy it to the cloud. In the entire process, you never write Kafka Streams code. The deployment process will automatically generate code in Kafka Streams. It will also perform configuration and security setup for you. While the pipeline is running, you can use Calabash KCE to monitor and manage it.
Calabash is a development platform for users to develop and deploy real-time ETL processes. But users do not need to write the most difficult parts of the processes.
Calabash does require some basic Java skills from the user. When it comes to the details of users’ business, they are the experts writing the processing expressions. On top of the Kafka Streams, Calabash wants to offer users complete freedom in processing those details.
If users feel more help is still needed, Data Canals also offers professional services. We will develop pipelines to your specification and provide follow-up maintenance service contracts. Please send us an inquiry at the Professional Service Inquiry page.
12. Further Reading
Calabash can also help you create readers and writers without writing code. Readers collect data from real-world sources into Kafka, and writers save data from Kafka to persistent media.
For the use case of readers, please check the article Collect Data to Kafka without Writing Code.
For the use case of writers, please check the article Saving Data from Kafka without Writing Code.
For a summary of all use cases of Calabash, please refer to the article Summary of Use Cases.
For product information about Calabash, please visit the Data Canals homepage.
The Calabash documentation site contains all the official articles from Data Canals. The documentation includes extensive tutorials that lead readers in a step-by-step learning process.
For theoretical-minded readers, we recommend the introductory article What is Data Lake. You will understand that Calabash has a much more ambitious goal than helping users use Kafka Streams.