This article is the user manual on creating lookups in Calabash GUI.
A lookup is a function from a key (of string type) to a scalar value. For example, given a product id, get a description of the product. Or given an item id, get its current price, etc.
Lookup is for enriching data during pipeline processing. Sometimes, you need data not available in the record. But if it has the key for the missing data, you can create a lookup to retrieve what you need.
Traditional relational databases use the join of tables in such cases. But in real-time pipelining, join is difficult, if not impossible, to do correctly. So the smart strategy is to avoid joins.
Using lookup by key for missing data is the next best thing without joins. But there may be performance concerns if the lookup table is accessed remotely for each lookup. Calabash implements a caching mechanism for the lookup table to cope with this challenge.
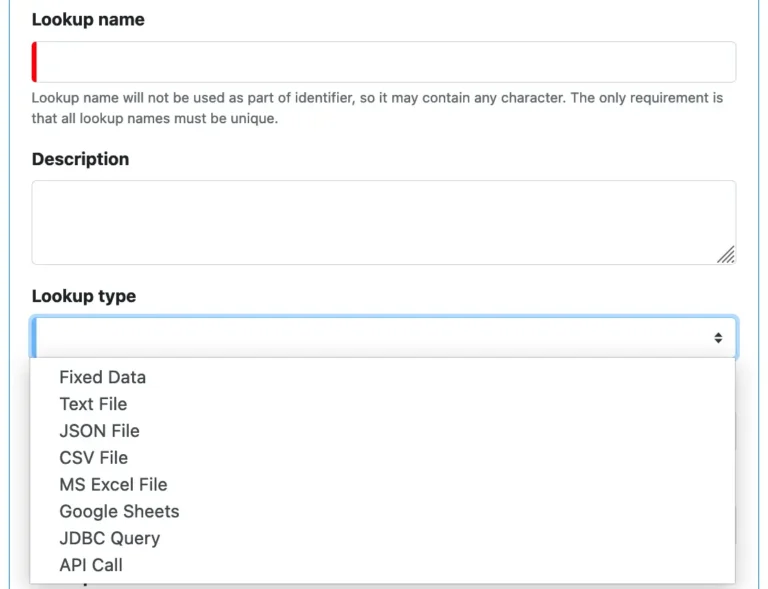
Calabash supports several types of lookups. In the create lookup form, clicking on the “Lookup types” property, you can see all the supported lookup types in a drop-down list. See the screenshot below.
When you select one from the lookup type list, you will see specific properties for the selected type. But before explaining the type-specific properties, we will first look at the common properties for all lookup types.
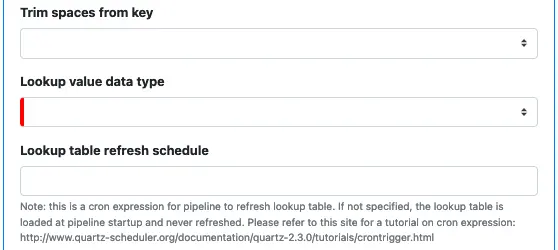
“Trim spaces from key” determines how you deal with leading and trailing spaces in the key string before using the key to search the lookup table. Possible options are:
Blank. No trimming of the key.
Trim both ends. Trim the key at both ends.
Trim left. Trim only the left side of the key.
Trim right. Trim only the right side of the key.
“Lookup value data type” defines the data type of the lookup result. The lookup result is a scalar type. Possible options:
string
boolean
int
long
float
double
“Lookup table refresh schedule” defines when Calabash must refresh the cached lookup table.
The following is how Calabash implements lookup. To improve lookup performance, Calabash preloads the lookup table into memory when a pipeline is starting.
The “JDBC Query” and “API Call” lookups preload a portion of the lookup table. All other lookups cache lookup tables in their entirety.
All the lookup searches happen in memory in the cached lookup table. If there is a miss in the cache, the lookup failed, except for “JDBC Query” and “API Call” lookups. For these lookup types, a miss in cache triggers accessing the remote site for result. Upon receiving a good return from the remote call, Calabash adds the new entry to the cached lookup table.
By default, the cached lookup table is initially empty for “JDBC Query” and “API Call” lookups. But you may ask Calabash to preload it with some entries at pipeline startup.
For all the lookup types, the cached lookup table is subject to becoming stale. Calabash automatically refreshes it based on a schedule. You use the “Lookup table refresh schedule” to add a cron expression to define this schedule. For the format of a cron expression, please read this page:
If you leave this property blank for a lookup, the automatic refresh is disabled. You will have to restart the pipeline to refresh the cached lookup table.
Now, let’s look at each lookup type and see what specific properties are associated with them.
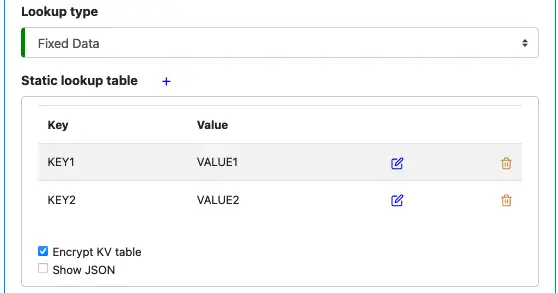
A “Fixed Data” lookup has a static lookup table, defined when you create the lookup using Calabash GUI.
As soon as you select “Fixed Data,” the property “Static lookup table” appears. You can use the interaction on this property to define the lookup table. The following screenshot shows an example of a static lookup table with two entries already added.
Click on the small blue plus sign to add a new entry in the lookup table.
Since the static lookup table is metadata of the lookup object, it will be in the Calabash repository. For security reasons, you may ask Calabash to store the lookup table in encrypted form. The “Encrypt KV table” flag is for that purpose.
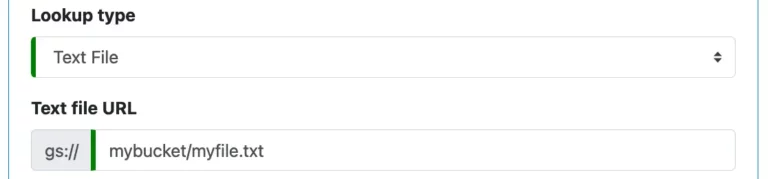
2. About "Text File" Lookup.
A “Text File” lookup searches in a plaintext file for lookup values. To create one, you first enter its location on Google storage.
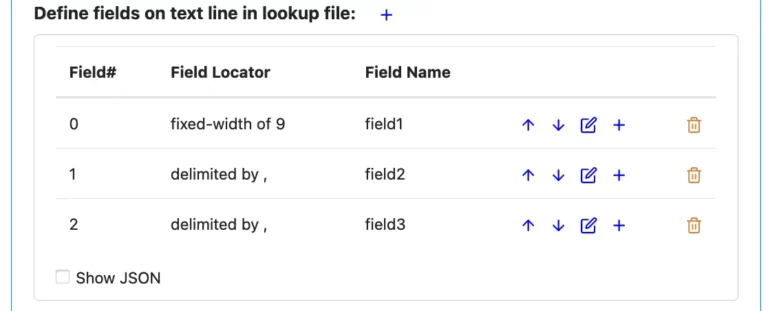
Each line in the text file is a lookup entry. It has key and value fields hidden in it. Next, you define how to cut the text line into consecutive text fields so that later you can assign the key and value roles to two of them.
Creating the field definitions is the same as in the text parser.
Once you have defined the text fields on the lookup line, you can map two fields to key and value, respectively. See below.
Also shown above, you can also say how many top lines in the file to skip when loading the lookup data.
3. About "JSON File" Lookup
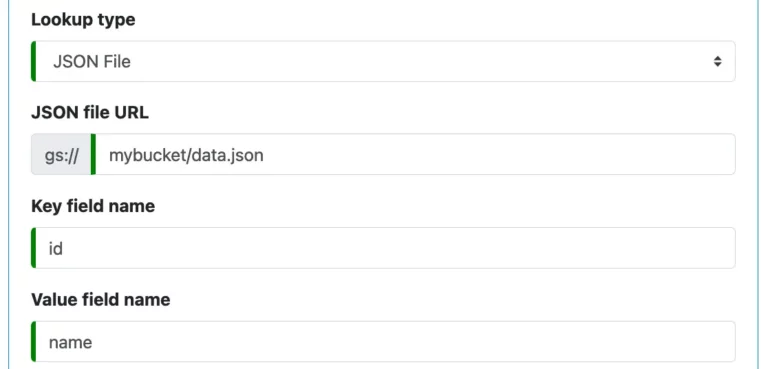
A “JSON File” lookup reads lookup data from a JSON file located on Google storage. Each line in the file is a serialized JSON object. There must be no comma at the end of each line, and the data must not be in square brackets.
You need to define the URL of the file and specify the field names of keys and values. And that is all you need to do.
4. About "CSV File" Lookup
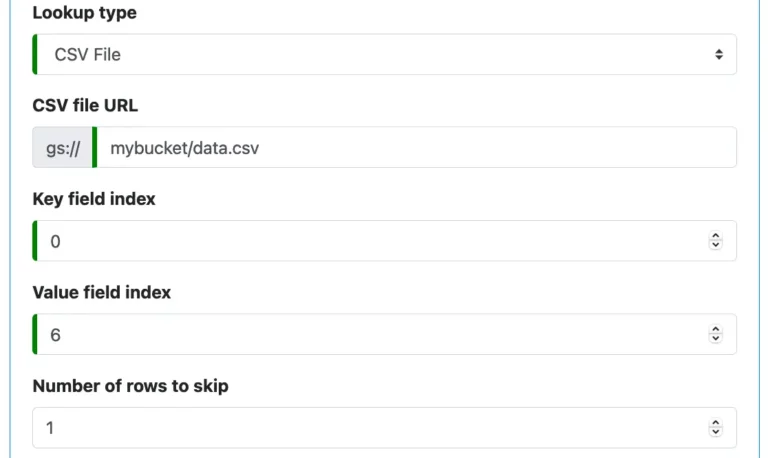
A “CSV File” lookup reads lookup data from a CSV file located on Google storage. Each line in the file is a lookup entry.
You define the URL of the file and field indexes for key and value (because a CSV file does not have field names). The field index starts from 0. You can also skip lines from the top of the file.
5. About "MS Excel File" Lookup
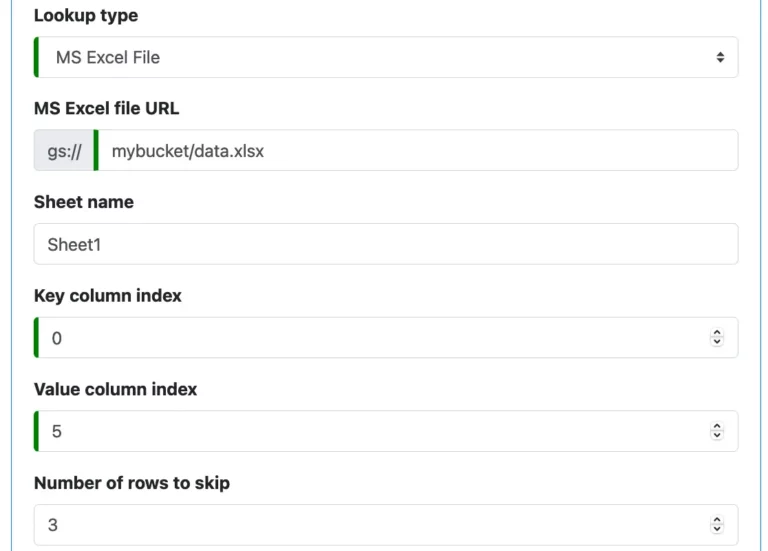
An “MS Excel File” lookup reads lookup data from a Microsoft Excel file located on Google storage. Each line in the file is a lookup entry.
You need to define the URL of the file and the sheet name. Then enter the column indices for key and value. Column index starts from zero. You can also ask to skip a few top lines in the file. See this screenshot.
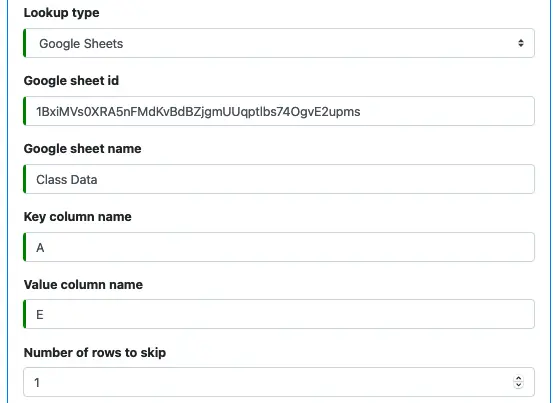
6. About "Google Sheets" Lookup
A “Google Sheets” lookup reads lookup data from a sheet on a Google Sheets site. Each line in the sheet is a lookup entry.
You need to define the id of the Google Sheets and the sheet name. Then enter the column names for key and value. You can also ask to skip a few top lines in the sheet. See this screenshot.
A “JDBC Query” lookup runs a SQL query to get the lookup value for a key. You enter the database connect string, username, and password. The format of the connect string is database-dependent. Please check the manuals for your database for details.
After that, you must enter a SQL statement. Usually, there is a bind parameter in the where-clause of the SQL statement. See the following example. A bind parameter is represented by a question mark.
The query result is the lookup value. You may need to add a data type conversion function in the above SQL statement to make the queried value compatible with the “Lookup value data type.” If the returned value is incompatible with the declared type, there will be a runtime exception.
Calabash caches lookup entries in memory to speed up lookup operation at runtime. For the JDBC source, the cached lookup table is initially empty. You may want to enter some most frequently used lookup keys in the “Prefetched keys” text area. Calabash will preload lookup entries for these keys during the initiation phase of your pipeline. Preloading the lookup table will drastically boost the performance of your data pipeline.
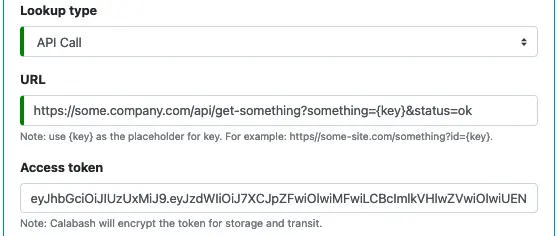
8. About "API Call" Lookup
An “API Call” lookup sends a GET call to an API service. The lookup key is placed in the URL as a parameter, like this:
In the above example, “something” is the lookup key name, and 100 is a key to search. The response contains the lookup value. Depending on the requirement from the API service, you may need to add more parameters, such as:
To start creating API Call lookup, select “API Call” as the lookup type. Then enter the API call URL. In this URL, you can use a placeholder “{key}” to represent the key to search. At runtime, Calabash replaces the placeholder with the actual key value (such as 100).
Optionally, you may enter an access token if your API service requires one. Most third-party services use access tokens as a means of authorization. The plaintext access token you entered here will be encrypted in the Calabash repository and decrypted in the pipeline.
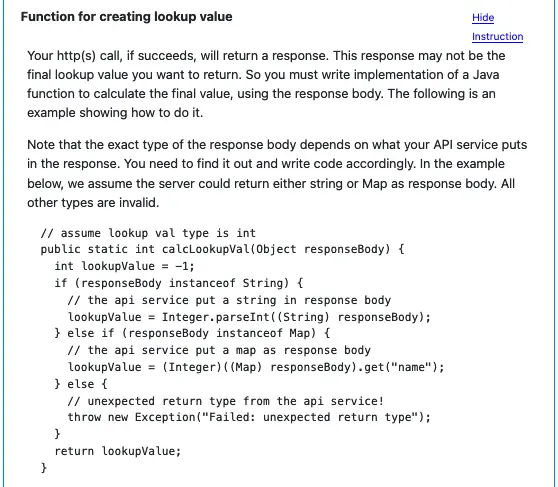
Next, you need to define a function to calculate the final lookup value from the API response object. Sometimes, the response body is already the lookup value. In this simple case, the function can be like this.
The function body above is what you need to enter. The function signature is there for your convenience.
More often than not, the lookup value you want is a part of the response body. In this case, you have to write a bit more complicated function to extract the final result. To see an example, click on the “Show Instruction” link, the instruction will show. See below.
Finally, you do not need to handle exceptions unless you intend to ignore the error. Any error will be escalated to processor level exception and will get processed there.